developer.nvidia.com
How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo
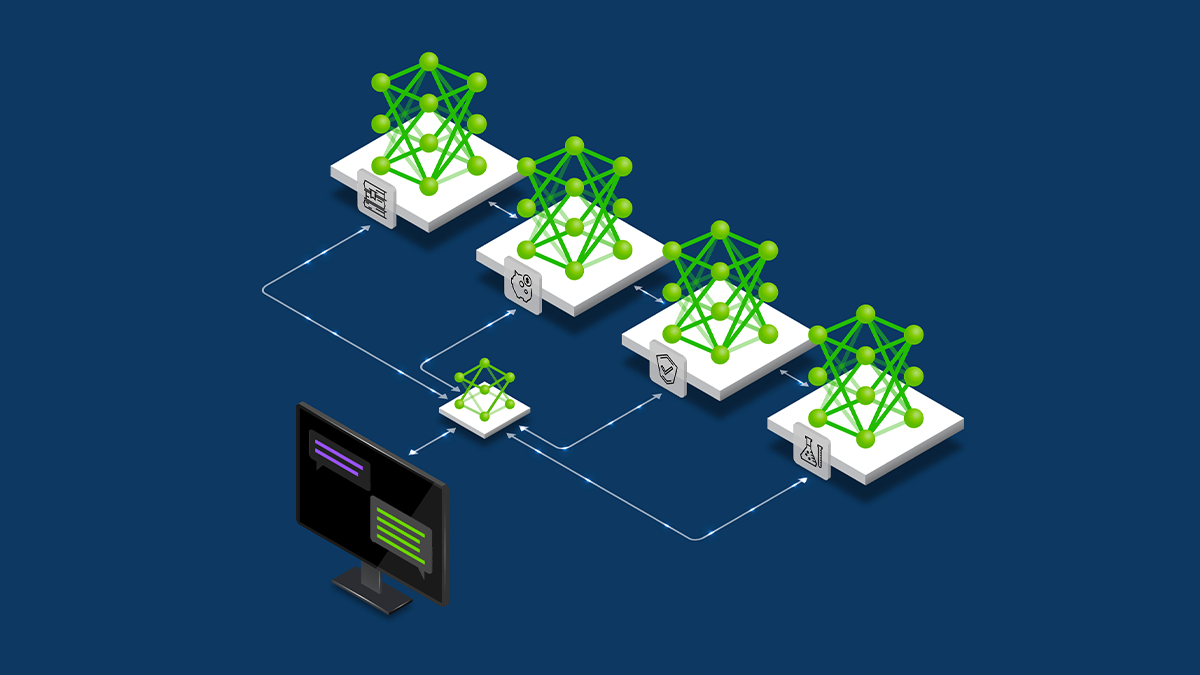
NVIDIA Dynamo offloads KV Cache from GPU memory to cost-efficient storage, enabling longer context windows, higher concurrency, and lower inference costs for large-scale LLMs and generative AI workloads.