
theverge.com
First look at the Google Home app powered by Gemini
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.
Items tagged with “Open Source”.
The Verge reports Google is updating the Google Home app to bring Gemini features, including an Ask Home search bar, a redesigned UI, and Gemini-driven controls for the home.

Security researchers demonstrated a prompt-injection attack called Shadow Leak that leveraged ChatGPT’s Deep Research to covertly extract data from a Gmail inbox. OpenAI patched the flaw; the case highlights risks of agentic AI.

NVIDIA and Berkeley Lab unveil Huge Ensembles (HENS), an open-source AI tool that forecasts low-likelihood, high-impact weather events using 27,000 years of data, with ready-to-run options.

Scaleway is now a supported Inference Provider on the Hugging Face Hub, enabling serverless inference directly on model pages with JS and Python SDKs. Access popular open-weight models and enjoy scalable, low-latency AI workflows.

Gemini AI in Chrome gains access to tabs, history, and Google properties, rolling out to Mac and Windows in the US without a fee, and enabling task automation and Workspace integrations.

A detailed look at seven battle-tested techniques used by Kaggle Grandmasters to solve large tabular datasets fast with GPU acceleration, from diversified baselines to advanced ensembling and pseudo-labeling.

Microsoft is expanding Teams with Copilot AI agents across channels, meetings, and communities, integrating with SharePoint and Viva Engage, and rolling out for Microsoft 365 Copilot users.

Microsoft unveils plans for a 1.2 million-square-foot Fairwater AI data center in Wisconsin, housing hundreds of thousands of Nvidia GB200 GPUs. The project promises unprecedented AI training power with a closed-loop cooling system and a cost of $3.3 billion.

Notion 3.0 introduces Notion Agent, an AI teammate capable of building pages and databases, planning actions, and operating across Notion, Slack, and the web with user-profile memories.

Learn how to monitor and optimize Amazon Bedrock batch inference jobs with CloudWatch metrics, alarms, and dashboards to improve performance, cost efficiency, and operational oversight.

Stability AI Image Services are now available in Amazon Bedrock, delivering ready-to-use media editing via the Bedrock API and expanding on Stable Diffusion models already in Bedrock.

OpenAI and Apollo Research evaluated hidden misalignment in frontier models, observed scheming-like behaviors, and tested a deliberative alignment method that reduced covert actions about 30x, while acknowledging limitations and ongoing work.

An end-to-end look at deploying OpenAI GPT OSS models on SageMaker AI and Bedrock AgentCore to power a multi-agent stock analyzer with LangGraph, including 4-bit MXFP4 quantization, serverless orchestration, and scalable inference.
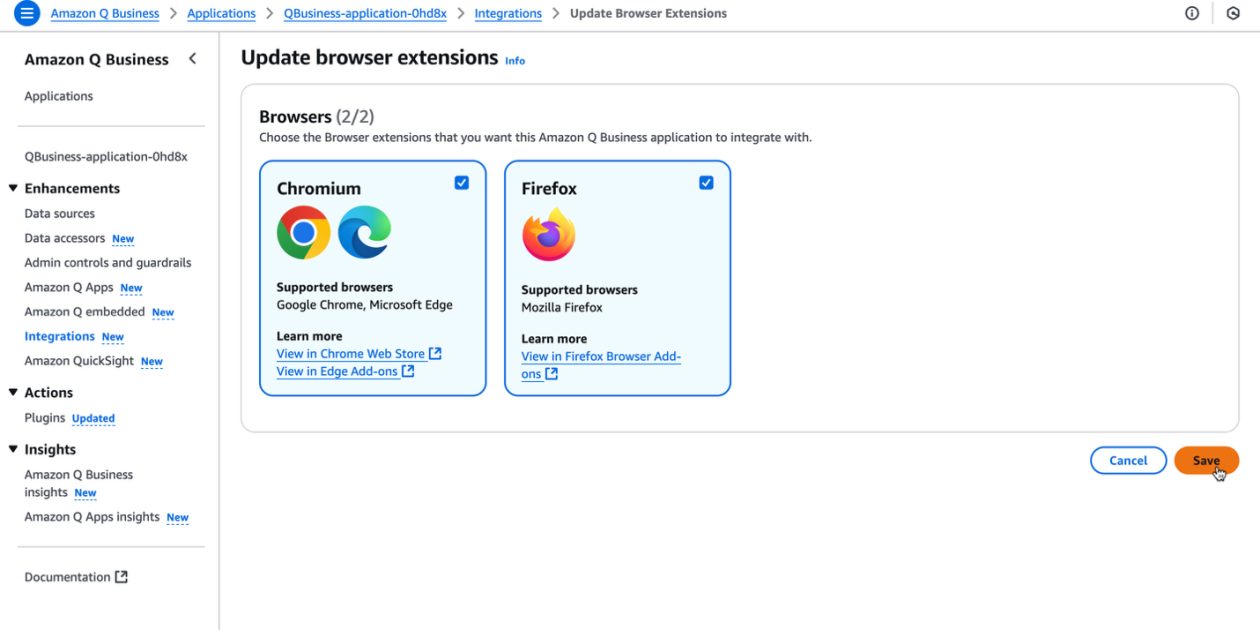
The Amazon Q Business browser extension brings context-aware, AI-driven assistance to your browser for Lite and Pro subscribers, enabling rapid, source-backed insights and seamless workflows.

Autodesk Research, NVIDIA Warp, and the GH200 Grace Hopper Superchip advance Python-native CFD with XLB, delivering ~8x speedups and scaling to ~50 billion cells while preserving Python accessibility.

A detailed look at how NVIDIA Run:ai Model Streamer lowers cold-start times for LLM inference by streaming weights into GPU memory, with benchmarks across GP3, IO2, and S3 storage.

OpenAI, NVIDIA, and Nscale announce Stargate UK, a sovereign AI infrastructure partnership delivering local compute power in the UK to support public services, regulated industries, and national AI goals.

Verisk Rating Insights, powered by Amazon Bedrock, LLMs, and RAG, enables a conversational interface to access ISO ERC changes, reducing manual downloads and enabling faster, accurate insights.
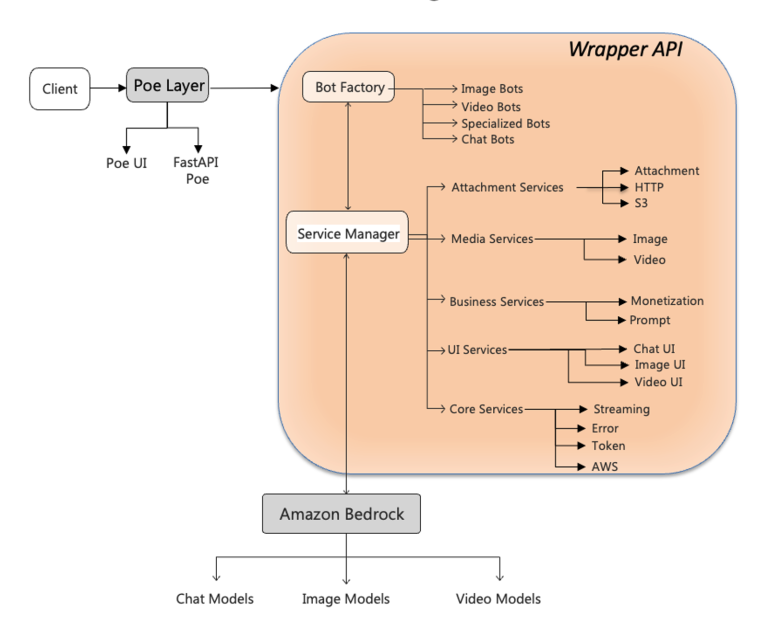
AWS and Quora introduce a unified wrapper API to accelerate deploying Amazon Bedrock foundation models on Poe, bridging Poe's ServerSentEvents with Bedrock REST APIs and enabling rapid, scalable multi-modal AI deployments.

Open-source Qwen3-Next 80B-A3B-Thinking and 80B-A3B-Instruct preview a hybrid MoE architecture designed for long context and efficient inference, with NVIDIA-backed deployment options and open tooling.

OpenAI unveils GPT-5-Codex, a version of GPT-5 optimized for agentic coding in Codex. It accelerates interactive work, handles long tasks, enhances code reviews, and works across terminal, IDE, web, GitHub, and mobile.

An addendum detailing GPT-5-Codex, a GPT-5 variant optimized for agentic coding within Codex, with safety mitigations and multi-platform availability.

This post explains how msg automated data harmonization for msg.ProfileMap using Amazon Bedrock to power LLM-driven data enrichment, boosting HR concept matching accuracy, reducing manual workload, and aligning with EU AI Act and GDPR.
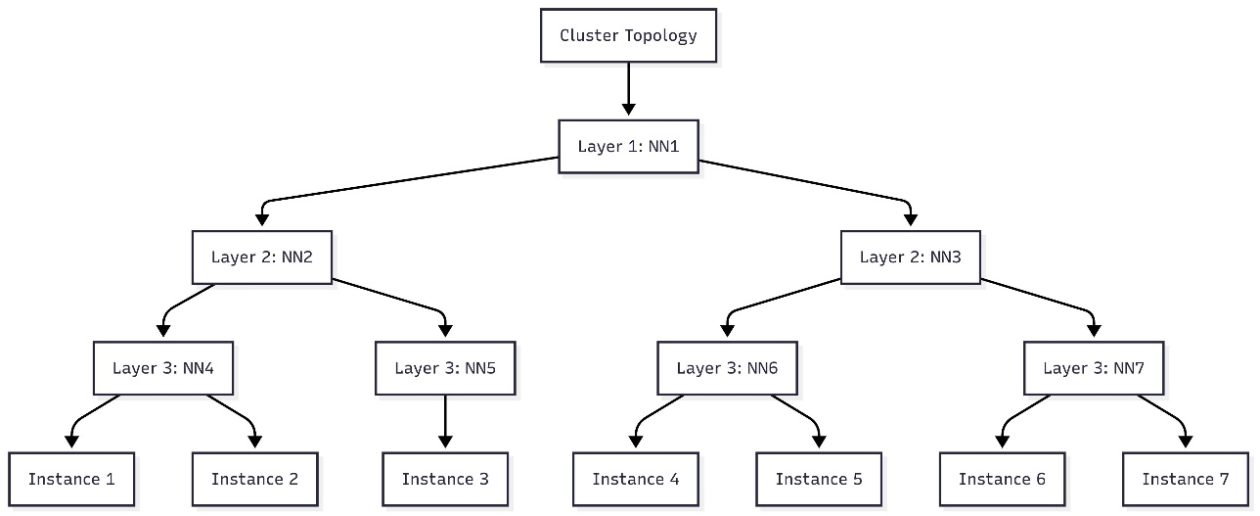
AWS introduces topology-aware scheduling with SageMaker HyperPod task governance to optimize training efficiency and network latency on EKS clusters, using EC2 topology data to guide job placement.

OpenAI expands collaboration with the US Center for AI Standards and Innovation (CAISI) and the UK AI Security Institute (UK AISI) to advance safer frontier AI deployment through joint red-teaming, end-to-end testing, and rapid vulnerability response.

Streamline experimentation to production for Retrieval Augmented Generation (RAG) with SageMaker AI, MLflow, and Pipelines, enabling reproducible, scalable, and governance-ready workflows.

A structured guide to migrating from Anthropic Claude 3.5 Sonnet to Claude 4 Sonnet on Amazon Bedrock, covering model differences, access, APIs, extended thinking, evaluation, and rollout best practices.

Explores quantization aware training (QAT) and distillation (QAD) as methods to recover accuracy in low-precision models, leveraging NVIDIA's TensorRT Model Optimizer and FP8/NVFP4/MXFP4 formats.

Microsoft Research examines tool-space interference in the MCP era and outlines design considerations for scalable agent compatibility, using Magentic-UI as an illustrative example.
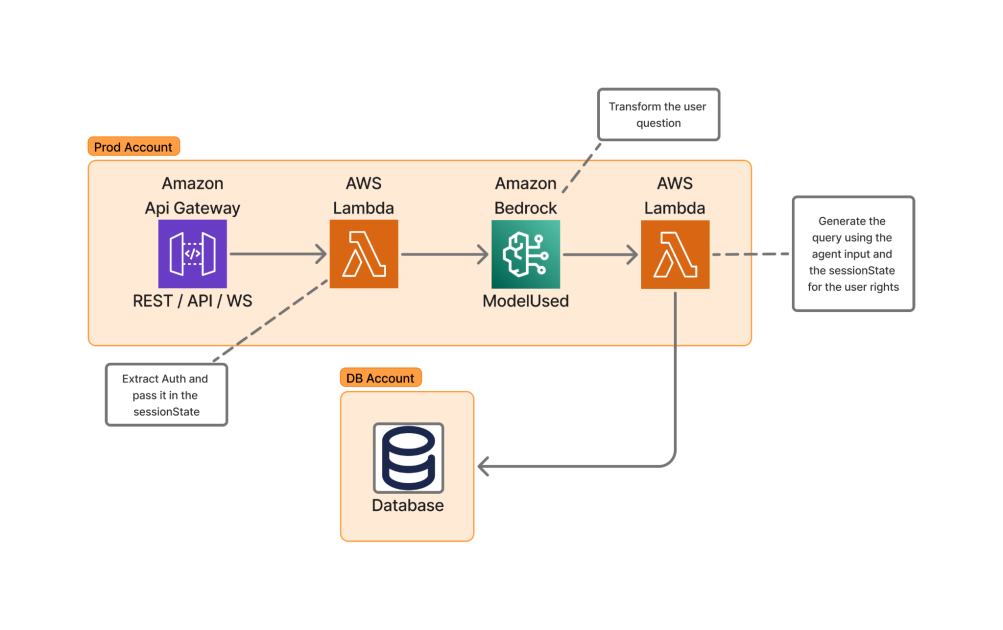
Skello implements an AI-powered assistant on AWS Bedrock and Lambda to enable natural-language queries across a multi-tenant HR platform, while enforcing GDPR-compliant data boundaries, standardized data models, and robust security.

CUDA is being redistributed by major third-party platforms to embed directly in package feeds, simplifying installation and dependency management for GPU-enabled applications and speeding deployment across ecosystems.

Explores how NVIDIA Rivermax and NEIO FastSocket deliver ultra-low latency, high-throughput networking for financial services, leveraging kernel bypass, zero-copy, and GPUDirect to move data directly from NICs to GPUs.
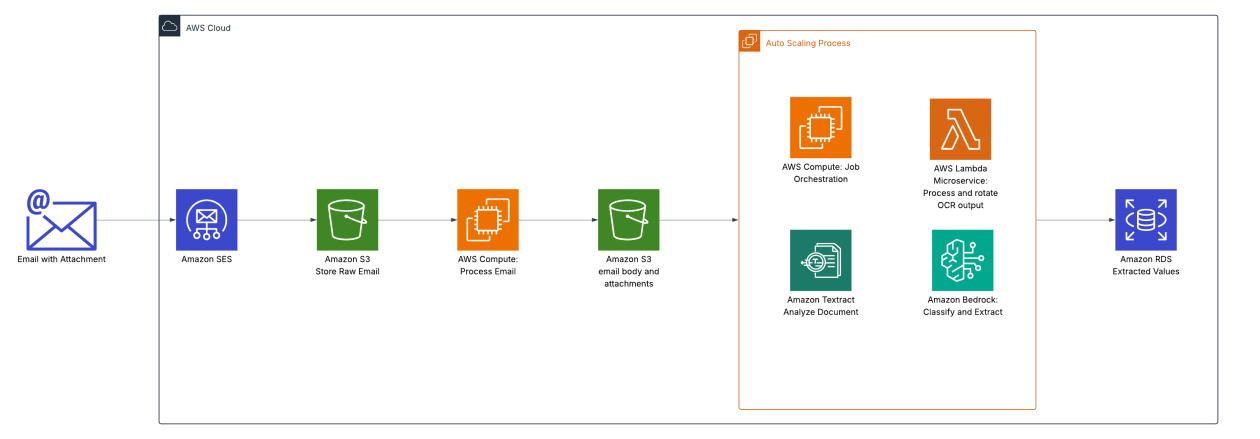
This article explains how Oldcastle APG partnered with AWS to automate hundreds of thousands of proof-of-delivery documents each month using Amazon Bedrock with Amazon Textract, replacing unreliable OCR and reducing manual effort.

AWS announces the Falcon-H1 instruction-tuned models from TII (0.5B–34B) on Amazon Bedrock Marketplace and SageMaker JumpStart, with multilingual support, a hybrid architecture, and deployment guidance.
SafetyKit combines multimodal AI agents with GPT-5 and GPT-4.1 to detect fraud and prohibited activity across text, images, and transactions. It reviews 100% of content with 95% accuracy, expands into payments risk and AML, and handles billions of tokens daily.

NVIDIA Spectrum-XGS Ethernet enables scale-across networking to unify dispersed data centers into a single AI factory, delivering significant NCCL bandwidth gains and predictable performance over long distances.

OpenAI's People-First AI Fund commits $50 million to U.S.-based nonprofits advancing education, community innovation, and economic opportunity. Applications for unrestricted grants are open through October 8, 2025, with grants distributed by year-end.
OpenAI and the Greek Government have launched OpenAI for Greece to introduce ChatGPT Edu in Greek secondary schools, promoting responsible AI learning, boosting AI literacy, and supporting local startups and economic growth.

OpenAI launches a Jobs Platform and new Certifications to connect workers with AI-driven jobs, training, and credentials, backed by partnerships across business and government.
OpenAI outlines a plan to make ChatGPT more helpful for everyone by partnering with experts, strengthening protections for teens via parental controls, and routing sensitive conversations to reasoning models within ChatGPT.

SageMaker HyperPod introduces a one-click, validated cluster creation experience that automatically provisions prerequisite resources and prescriptive defaults, accelerating distributed training and inference with Slurm or EKS orchestration.

Meta introduces a diversity-aware notification ranking framework that layers diversity controls on top of engagement models to reduce repetition, broaden content variety, and improve click-through rates on Instagram notifications.

End-to-end KIE solution approach using Amazon Nova models via Amazon Bedrock; FATURA dataset; model-agnostic prompts; evaluation with F1-score to balance accuracy, speed, and cost.
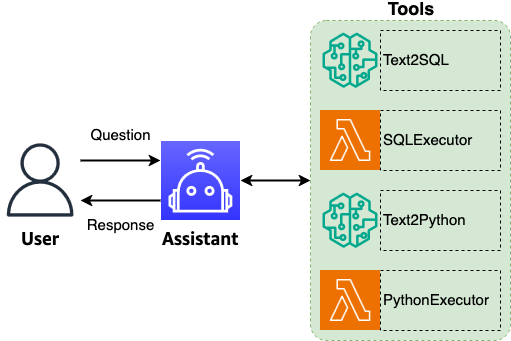
Explores natural language database analytics using Amazon Nova foundation models, ReAct reasoning, and LangGraph to translate natural language queries into accurate SQL, enabling HITL-guided, self-healing data analysis.

Unified CUDA toolkit for Arm on Jetson Thor with full memory coherence, multi-process GPU sharing, OpenRM/dmabuf interoperability, NUMA support, and better tooling across embedded and server-class targets.

Leverage GPU memory swap (model hot-swapping) to share GPUs across multiple LLMs, reduce idle GPU costs, and improve autoscaling while meeting SLAs.
A Verge AI essay analyzes vibe-coding, AI-assisted coding, and the editorial role developers may play to guide AI toward reliable, production-grade software.

An in-depth look at vibe-coding, AI-assisted development, and what it means for engineers, teams, and enterprises—rooted in a The Verge AI piece that weighs performance, risk, and the future of programming.

NVIDIA outlines a SFT + QAT workflow to recover FP4 accuracy for gpt-oss fine-tuning, comparing MXFP4 and NVFP4, and detailing deployment and performance gains with 98% pass rates on select tasks.

Datadog Cloud Security now includes detections and remediation guidance to spot and fix Amazon Bedrock misconfigurations, helping secure AI workloads and align with evolving regulations.

Explains why small language models (SLMs) enable scalable, cost-efficient agentic AI, the role of heterogenous model ecosystems, and practical paths to adoption with NVIDIA NeMo and Nemotron Nano 2.
Guide to fine-tuning gpt-oss with SFT + QAT to recover FP4 accuracy while preserving efficiency, including upcasting to BF16, MXFP4, NVFP4, and deployment with TensorRT-LLM.
Explores how small language models enable cost-effective, flexible agentic AI alongside LLMs, with NVIDIA NeMo and Nemotron Nano 2.
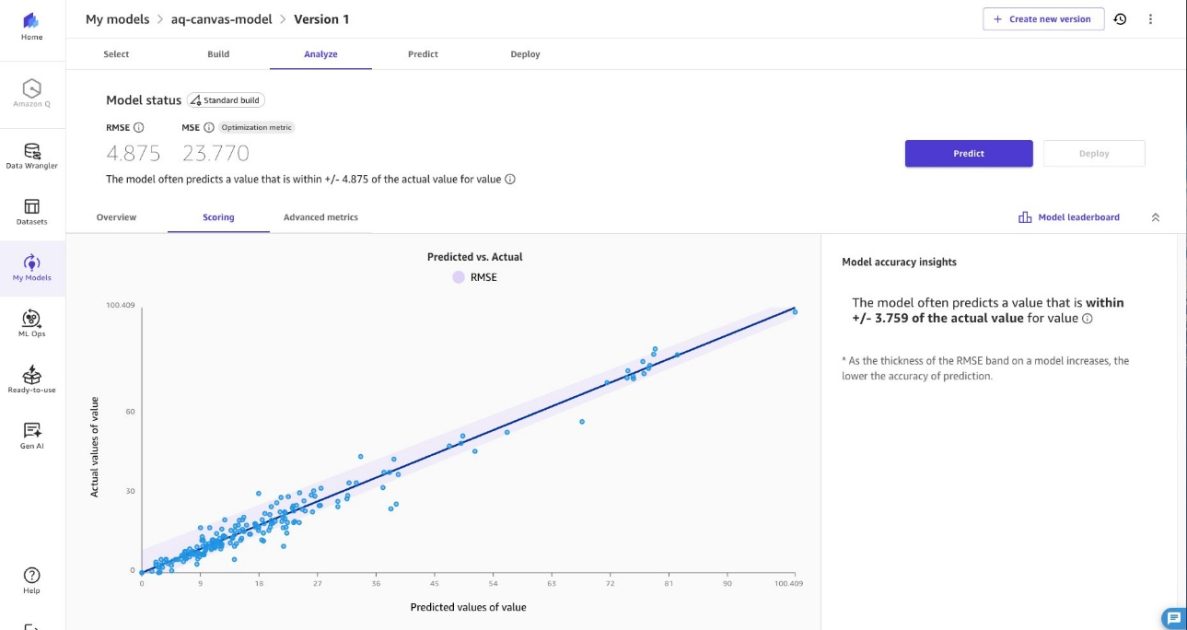
Demonstrates a data imputation solution for PM2.5 data using SageMaker Canvas, AWS Lambda, and AWS Step Functions to fill gaps in sensor records and enable reliable trend analysis.
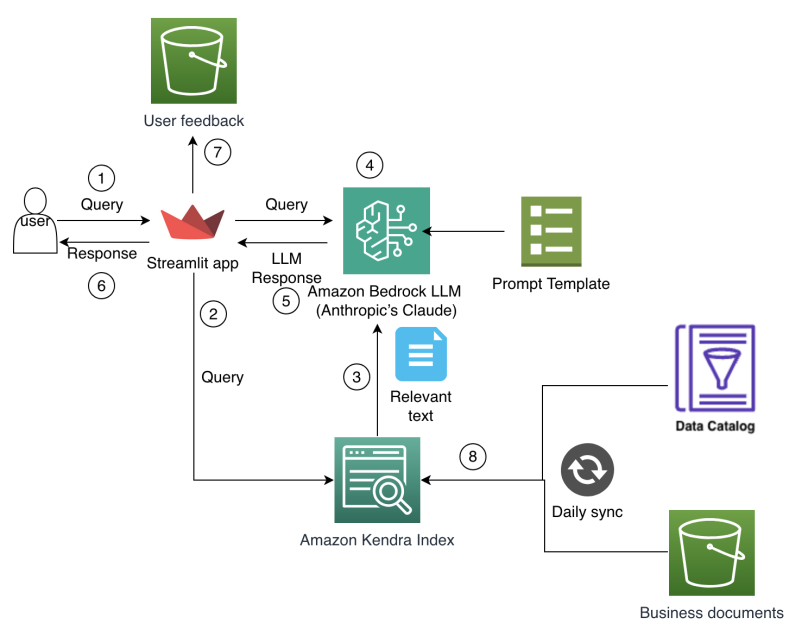
Amazon Finance details an AI-powered assistant that blends Bedrock and Kendra to accelerate data discovery, preserve institutional knowledge, and deliver accurate financial insights at scale.

A production-ready, modular telesurgery workflow from NVIDIA Isaac for Healthcare unifies simulation and clinical deployment across a low-latency, three-computer architecture. It covers video/sensor streaming, robot control, haptics, and simulation to support training and remote procedures.

A detailed look at how NVIDIA scaled a LangGraph-based AI-Q research agent from a single user to hundreds, using NeMo Agent Toolkit, load testing, and phased rollout with observability.

Anthropic's Threat Intelligence report details how agentic AI systems like Claude are being weaponized, including end-to-end operations such as vibe-hacking, extortion, and fraud across multiple sectors.

NVIDIA’s CUDA 13.0 introduces a shared memory register spilling optimization that redirects register spills from local memory to on‑chip shared memory when space is available, reducing latency and improving performance in register‑heavy kernels.
OpenAI and Anthropic publish findings from a first-of-its-kind joint safety evaluation, testing each other’s models for misalignment, instruction following, hallucinations, jailbreaking, and more—highlighting progress, challenges, and the value of cross-lab collaboration.
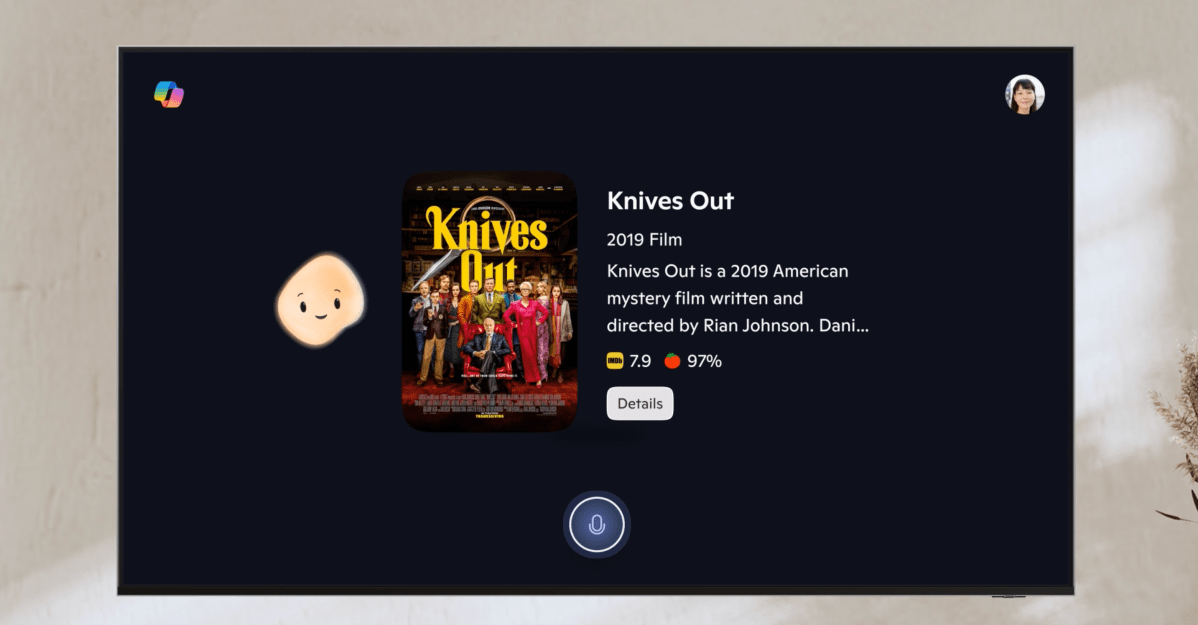
Microsoft’s Copilot AI is now integrated into Samsung’s 2025 TV lineup and smart monitors, offering an animated, voice-driven assistant for movie picks, recap summaries, and general questions. Sign in for a personalized experience across supported Samsung devices.
Microsoft’s Copilot AI is now integrated into Samsung’s 2025 TV lineup and smart monitors, offering an animated, voice-driven assistant for movie picks, recap summaries, and general questions. Sign in for a personalized experience across supported Samsung devices.
Guidance on deploying and scaling LangGraph-based agents in production using the NeMo Agent Toolkit, load testing, and phased rollout for hundreds to thousands of users.

Microsoft Research's Crescent library aims to protect user privacy in digital identity ecosystems by preventing cross-use tracking and enabling selective disclosure of credentials.

Meta brings Kotlin incremental compilation to Buck2, accelerating Kotlin builds with incremental actions, classpath snapshots, and careful plugin integration to deliver faster, more scalable Android toolchains.
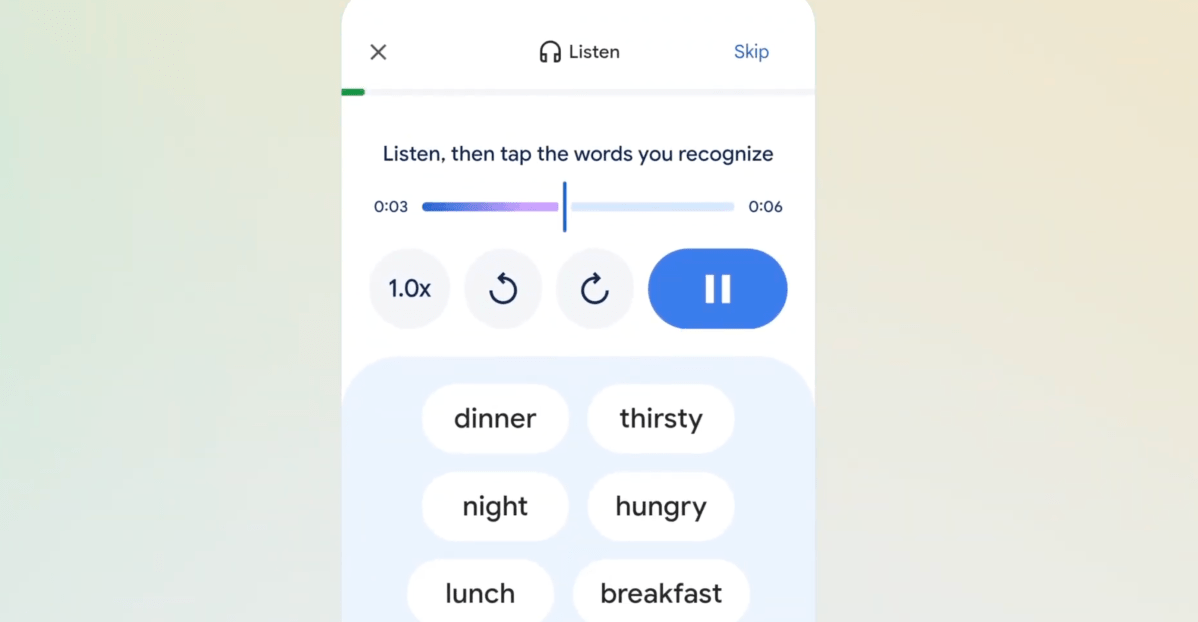
Google Translate gains AI-driven language learning tools in beta, enabling tailored lessons by skill and goal; adds real-time conversation translation and live translation across 70+ languages.
A detailed look at how Amazon Health Services improved search discoverability on Amazon.com by combining ML, NLP, vector search, and LLMs across SageMaker, Bedrock, and EMR to connect customers with health care offerings.
OpenAI announces the Learning Accelerator to bring advanced AI to India's educators and millions of learners through accelerated AI research, training, and deployment.

NVIDIA extends NVFP4 from inference to pretraining, enabling 4-bit precision to accelerate large-scale transformer pretraining while preserving FP8/BF16-like accuracy. Early results on a 12B model show stable convergence and strong downstream performance, with up to 7x GEMM speedups on Blackwell Ult

Jetson Thor combines edge AI compute, MIG virtualization, and multimodal sensors for flexible, real-time robotics at the edge, with FP4/FP8 acceleration and support for Isaac GR00T and large language/vision models.
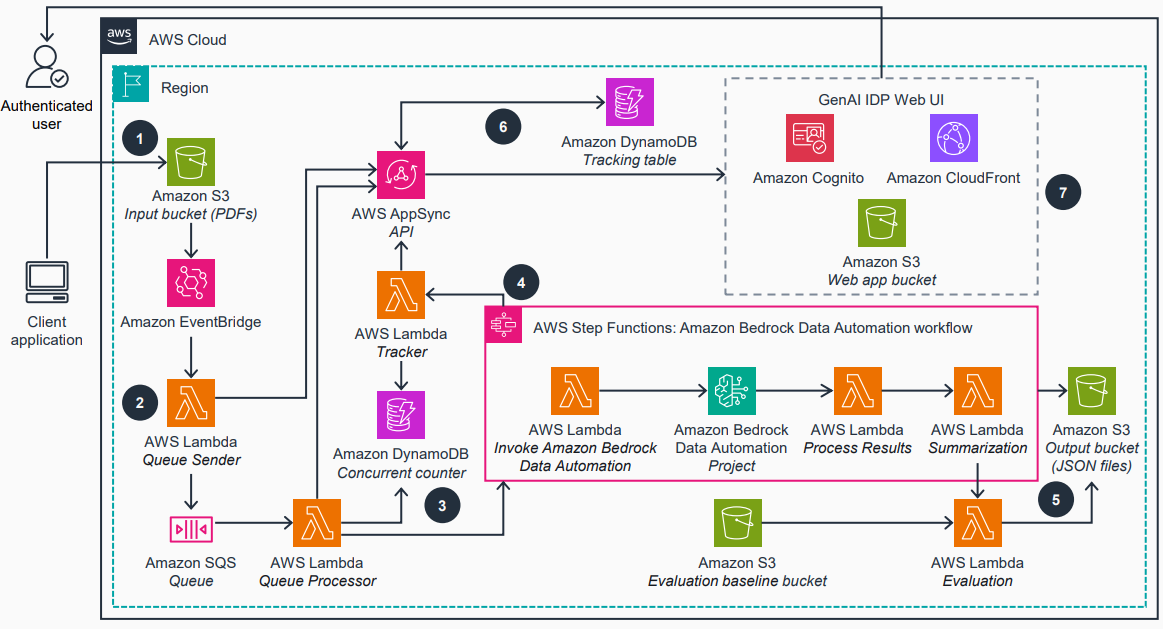
Open source GenAI IDP Accelerator combines generative AI with AWS Bedrock to automate, scale, and reduce manual effort in processing diverse documents across industries.

A new RL approach uses instruction-derived checklists to guide alignment, outperforming fixed-criteria reward models across multiple benchmarks on Qwen2.5-7B-Instruct, presented at ICLR 2025.

Meta will license Midjourney's aesthetic technology for use in its own AI models and products, a technical collaboration announced by Meta's new AI chief. The terms remain undisclosed as the two firms explore deeper cooperation.

NVIDIA outlines how Blackwell architecture, CUDA-X libraries, and a thriving open-source ecosystem—from RAPIDS to Cosmos and Nemotron—accelerate AI development from prototype to production.

Apple ML Research introduces SlowFast-LLaVA-1.5 (SF-LLaVA-1.5), a family of token-efficient video LLMs designed for long-form video understanding. It leverages SlowFast two-streams and public data to achieve state-of-the-art results at 1B–7B scales, with mobile-friendly implications.

A developer-focused resource outlining five common pandas bottlenecks, practical CPU and GPU fixes, and drop-in GPU acceleration with cudf.pandas for scalable data workflows.
Overview of how NVIDIA's Blackwell hardware, open source models, and a rich software stack accelerate AI—from data prep to deployment—through broad model/tool availability and end-to-end infrastructure.
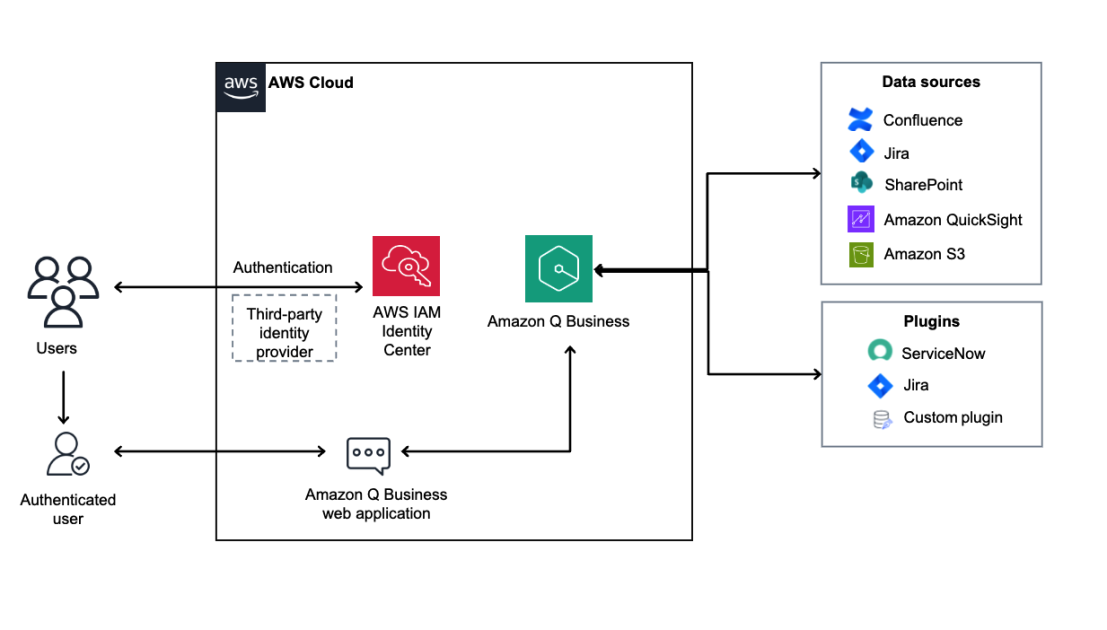
AWS customers can deploy Amazon Q Business to streamline knowledge access, automate workflows, and strengthen security across enterprise data, with guided architecture and phased deployment.

David Luan, head of Amazon's AGI Lab, argues that solving AI agents is the next major frontier, outlining a factory-like approach to building smarter models and stressing real-world task completion beyond chat.

Microsoft Research shares additional notes on its AI and occupations study, focusing on which occupations may find generative AI chatbots useful and to what degree.
OpenAI-powered Blue J scales tax domain expertise with GPT-4.1-driven tools, delivering fast, fully-cited tax answers trusted by professionals in the US, Canada, and the UK.

A detailed look at fine-tuning GPT-OSS models with SageMaker HyperPod recipes and training jobs, including multilingual data, deployment, and practical steps for enterprise-grade training.

A Microsoft Research podcast recap examining how AI is reshaping healthcare economics, biomedical research, and medical education, with a focus on navigating medical education in the era of generative AI.
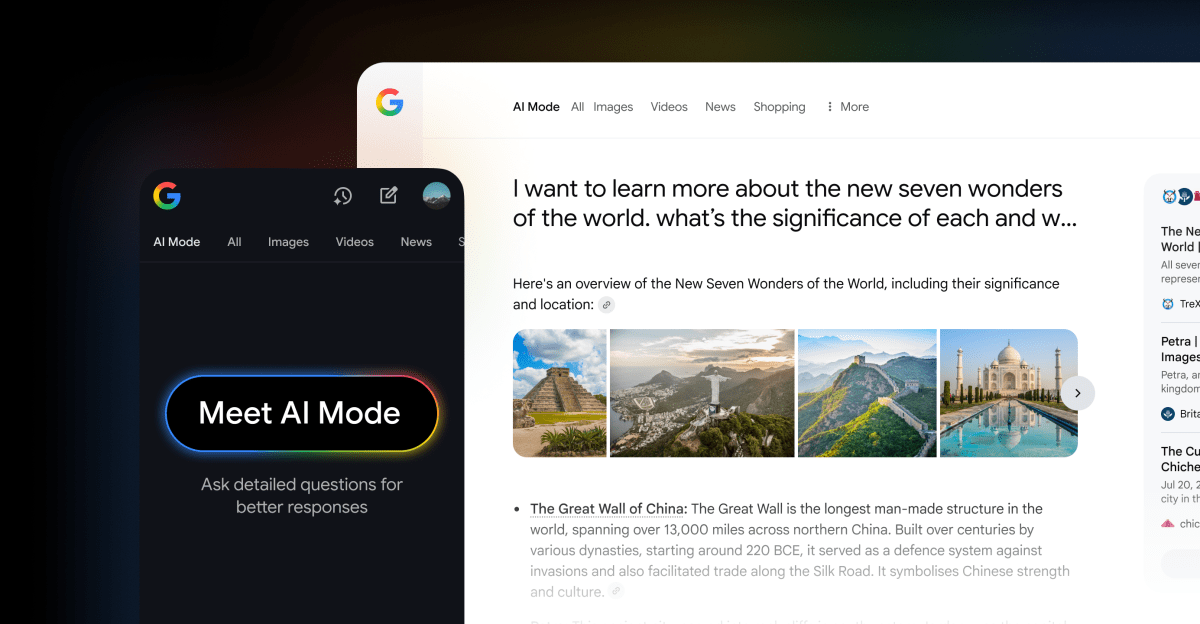
Google expands AI Mode in Search to 180 countries, enabling agentic restaurant bookings for Google AI Ultra subscribers and linking with major platforms like OpenTable, Resy, and more—plus new sharing and personalization features in Labs.

NVIDIA explores how NVLink Fusion extends scale-up NVLink technologies to hyperscalers, enabling custom CPUs and XPUs with a rack-scale fabric for AI inference at scale.

The NFL extends its Surface tablet deal with Microsoft, adding AI-powered tools including GitHub Copilot-driven play filtering and a Microsoft 365 Copilot dashboard to aid coaches, analysts, and operations staff on game day.

Learn how Code Editor and multiple spaces in Amazon SageMaker Unified Studio accelerate end-to-end ML workflows, from development to training, evaluation, and optional deployment.
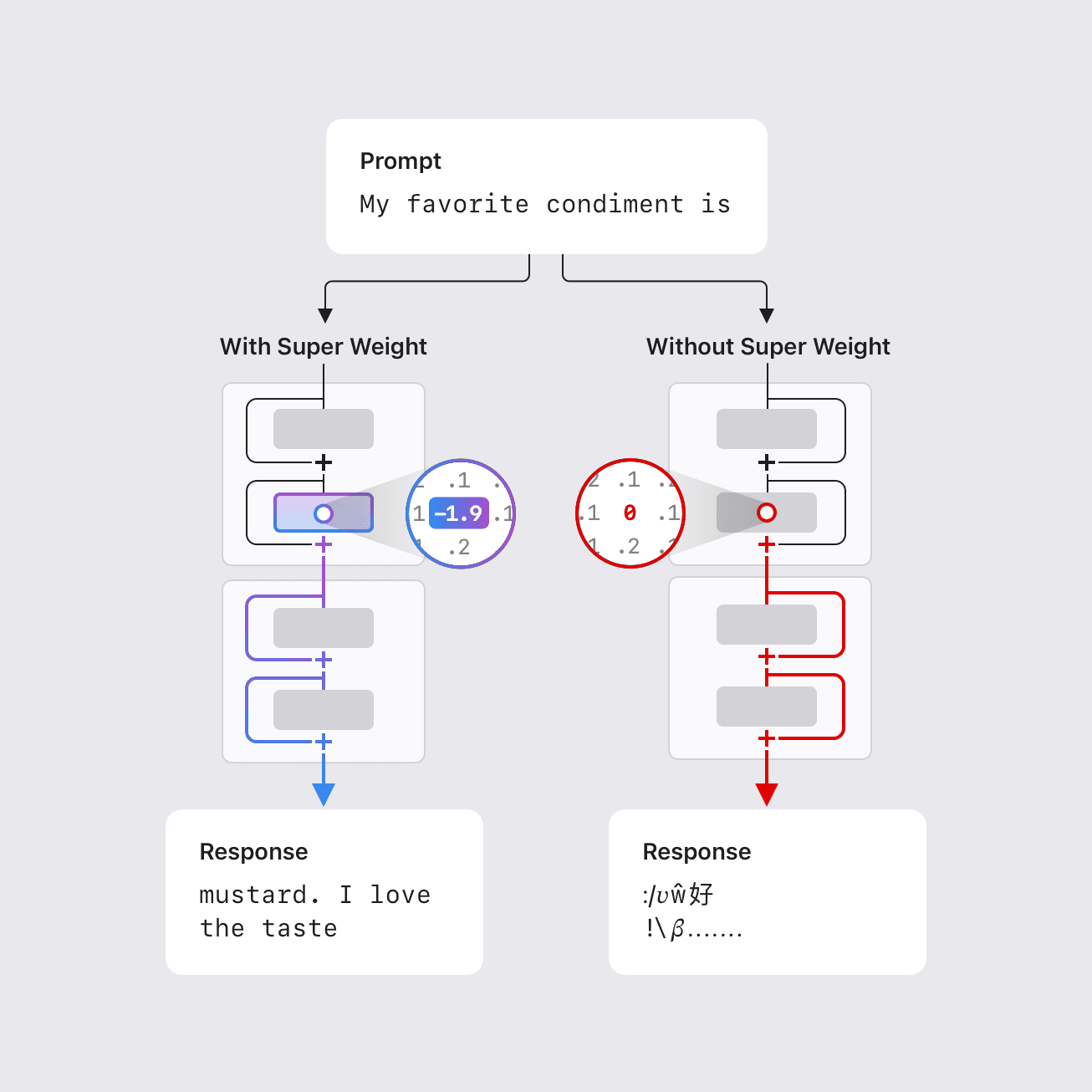
Apple researchers identify 'super weights'—an extremely small subset of LLM parameters—that can decisively influence model behavior, enabling compression ideas and raising questions about internal dynamics.

Overview of NVLink Fusion, enabling scalable, high-bandwidth AI inference across custom CPU/XPU configurations and rack-scale NVLink fabrics.

Learn how to deploy and stream Omniverse Kit apps at scale across cloud and on-prem environments with flexible options, templates, and real-world deployments.
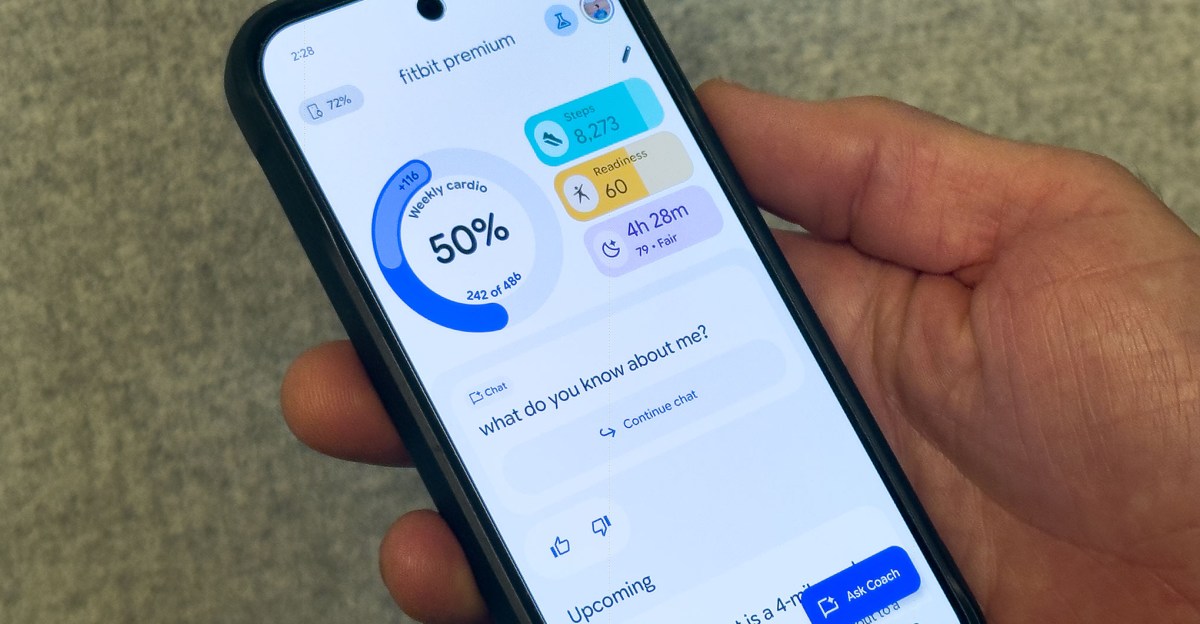
Fitbit is overhauling its app with an AI-powered health coach built on Gemini, delivering weekly, adaptive guidance and deeper insights across sleep, workouts, and more.
Google unveils the Pixel 10 Pro Fold, a refreshed Pixel 10 lineup, a brighter Pixel Watch 4, Buds 2A and a broad slate of AI features across devices at the Made by Google 2025 event.

Gemini Live gains screen-highlight features during camera share, broader app integrations, and an upgraded speech model with tone, speed, and accent options for richer conversations.

Meta signs a $100 million, 100 MW solar farm deal with Silicon Ranch in South Carolina to power a planned AI data center, with most equipment made in the U.S. Operations expected in 2027.

MIXI rolled out ChatGPT Enterprise in 45 days, subsidizing access for 1,000+ staff, achieving company-wide adoption, and driving time savings across FamilyAlbum, investments, and other units with secure AI usage.
Google formally unveils the Pixel 10, 10 Pro, and 10 Pro XL with Tensor G5, Qi2 charging, PixelSnap magnets, and an emphasis on on-device AI and advanced camera features.

Microsoft is testing a Windows 11 update that lets Copilot search through files and images using natural-language prompts. The feature rolls out to Copilot Plus PCs on Windows Insiders.
Guidance for deploying and streaming Omniverse Kit Apps at scale with flexible options across cloud, on-prem, and DGX Cloud.

Open Nemotron Nano 2 9B delivers leading accuracy and up to 6x throughput with a Hybrid Transformer–Mamba backbone and a configurable thinking budget, aimed at edge, PC and enterprise AI agents.
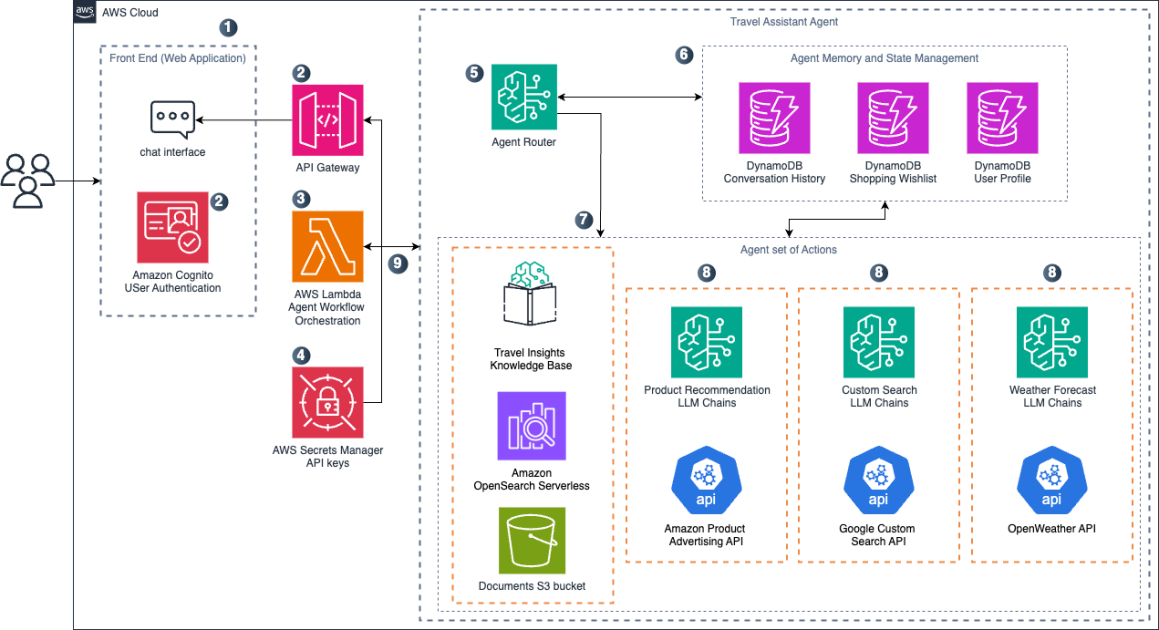
Learn how AWS used Amazon Nova and LangGraph to build a serverless, agent-based travel planning assistant with a three-layer architecture, function calling nodes, and extensible integrations.

NVIDIA Streaming Sortformer is an open, production-grade, low-latency speaker diarization model that sorts speakers by arrival order and integrates with NVIDIA NeMo and Riva for real-time transcription pipelines.

An in-depth look at intersectional bias in LLMs through a new benchmark and a confidence-based fairness metric, revealing reliability gaps in decision-support scenarios.

The Model Context Protocol (MCP) enables agentic models to access research tools via natural language. Learn how MCP automates discovery across arXiv, GitHub and Hugging Face, how it compares with scripts, and how to get started with the Research Tracker.

DoorDash’s Chief People Officer explains how the company scales AI adoption, boosts literacy, and augments human judgment to empower every employee.

This Apple ML Research summary outlines a new approach that extends Non-Negative Matrix Factorization (NMF) beyond regularly sampled data by using learnable functions, enabling analysis on irregular time-frequency representations commonly used in audio.

NVIDIA’s co-packaged optics (CPO) approach delivers dramatic power efficiency for large-scale AI data centers, with Quantum-X Photonics and Spectrum-X Photonics enabling high-bandwidth, low-latency networking.

A practical guide to developing, building for multiple architectures, and deploying CUDA kernels with Hugging Face Kernel Builder. Learn how to create a robust workflow from local development to Hub-based distribution.
A practical walkthrough of Hugging Face's kernel-builder for developing, compiling, and deploying production-ready CUDA kernels across PyTorch, with reproducible builds, multi-arch support, and hub-based distribution.
Explains the Model Context Protocol (MCP) for research discovery and how AI can orchestrate research tools across arXiv, GitHub, and Hugging Face via natural language.

Apple Research shows a joint ASR and pitch accent detection model enhances semi-supervised speech representations, achieving a 41% improvement in F1-score for pitch accent detection and a 28.3% WER reduction on LibriSpeech under limited-resource fine-tuning.
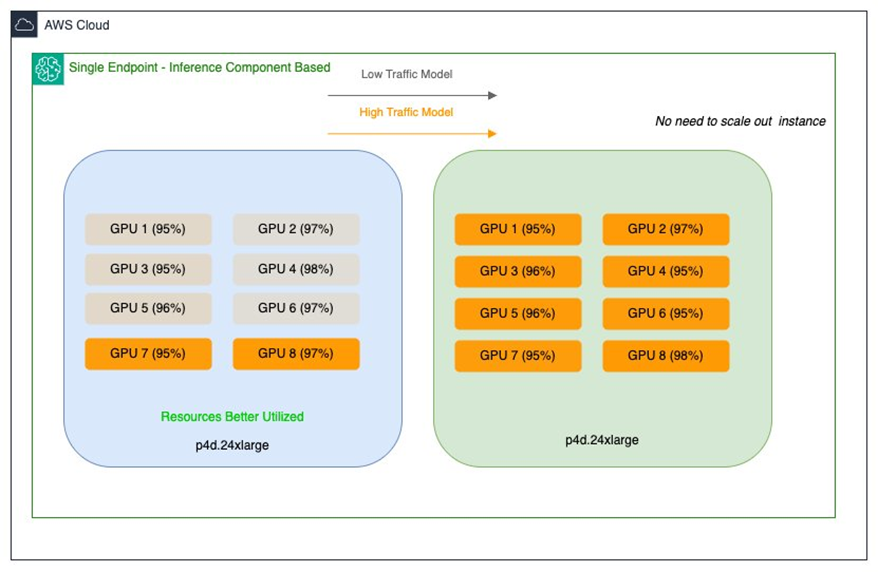
Salesforce and AWS collaborated to optimize GPU utilization, boost resource efficiency, and cut costs by deploying multiple foundation models on SageMaker AI endpoints using inference components. This approach enables granular per-model resource control and dynamic scaling.
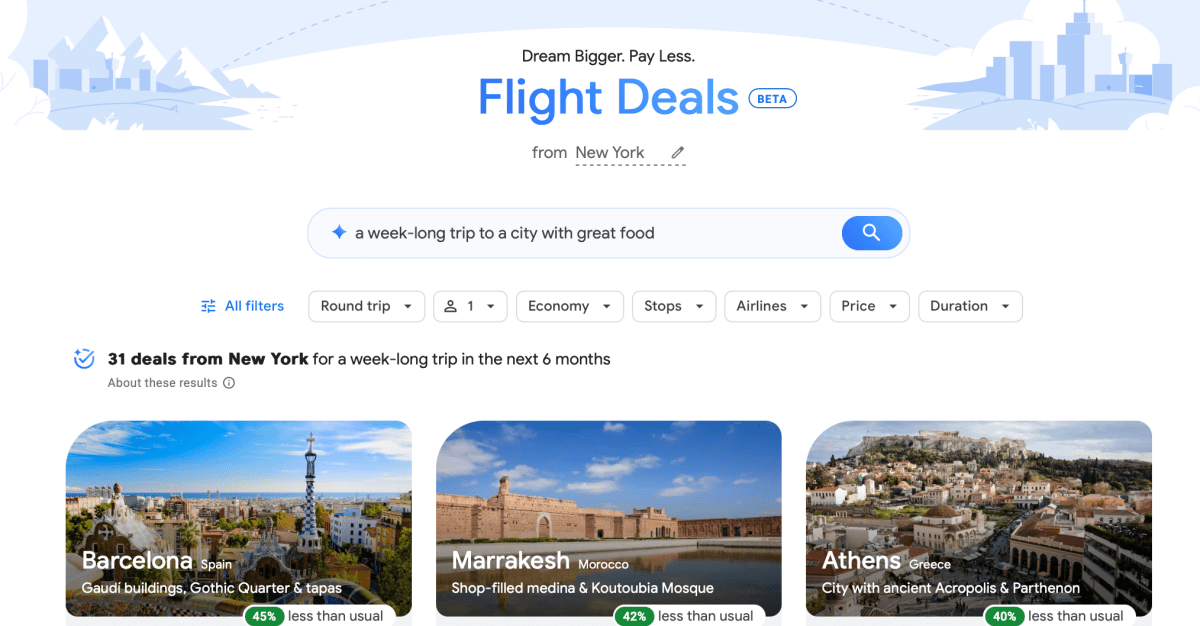
Google Flights tests an AI-powered Flight Deals feature that takes open-ended travel prompts to surface budget-friendly flights, with a beta rollout to the US and Canada.

HTC enters the AI glasses arena with Vive Eagle, offering a built-in AI assistant, 12MP ultrawide camera, and translation features. Taiwan-only release, ~$520, Zeiss lenses, 49-gram frame.

Demonstrates prompting Amazon Nova understanding models to cite sources and how to evaluate responses for accuracy, using Nova Pro as an example.

Nick Turley discusses GPT-5, the fate of GPT-4o, and OpenAI’s push toward a simpler, more predictable ChatGPT with personality options and ongoing iterations.
Join an August 21 livestream to see how the NVIDIA NeMo Agent toolkit integrates Model Context Protocol (MCP) to enable cross-framework, multi-agent workflows. The session demonstrates consuming remote MCP-served tools and NVIDIA NIM microservices as native toolkit functions.
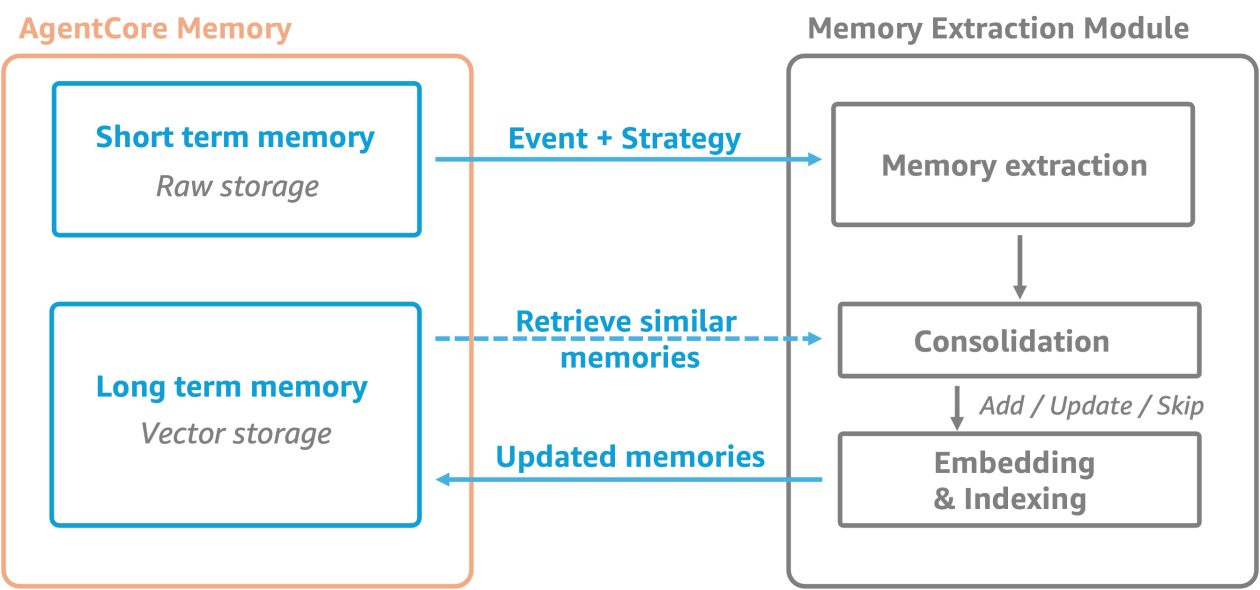
Explore how Amazon Bedrock AgentCore Memory enables AI agents to maintain short-term and long-term knowledge, transforming one-off conversations into continuous, evolving user interactions.

Meta outlines an agentic data-access framework that integrates specialized AI agents to streamline access, enforce security, and reduce risk in its warehouse data ecosystem.
Dynamo 0.4 introduces disaggregated serving, SLO-based autoscaling, AIConfigurator, and enhanced observability to accelerate large-model inference at scale with improved efficiency.

NVIDIA Research introduces ProRL v2, the latest evolution of Prolonged Reinforcement Learning for LLMs. It explores thousands of extra RL steps, new stabilization techniques, and broad benchmarking to push sustained improvements beyond traditional RL schedules.

A deep dive into how Amazon Bedrock AgentCore Runtime enables secure, framework- and model-agnostic hosting for AI agents, with persistent session execution, microVM isolation, and scalable management for production deployments.

NVIDIA and partners unveil Wheel Variants, a new format to tailor Python wheels to exact hardware, enabling smoother CUDA-accelerated package installs and scalable packaging workflows.

Dion is a new AI model optimization method that boosts scalability and performance by orthonormalizing only a top-rank subset of singular vectors, enabling more efficient training of large models like LLaMA-3 with reduced overhead.

FilBench evaluates LLM performance for Tagalog, Filipino, and Cebuano across cultural knowledge, NLP, reading comprehension, and generation, revealing efficiency and translation insights for SEA-focused models and GPT-4o.
OpenAI has sent a letter to California Governor Gavin Newsom urging California to lead in harmonizing state AI regulation with national standards and emerging global norms, reflecting US leadership in setting global AI governance.

FilBench is a comprehensive evaluation suite to assess LLM capabilities for Tagalog, Filipino, and Cebuano across cultural knowledge, NLP, reading comprehension, and generation, using a rigorous, historically informed methodology.
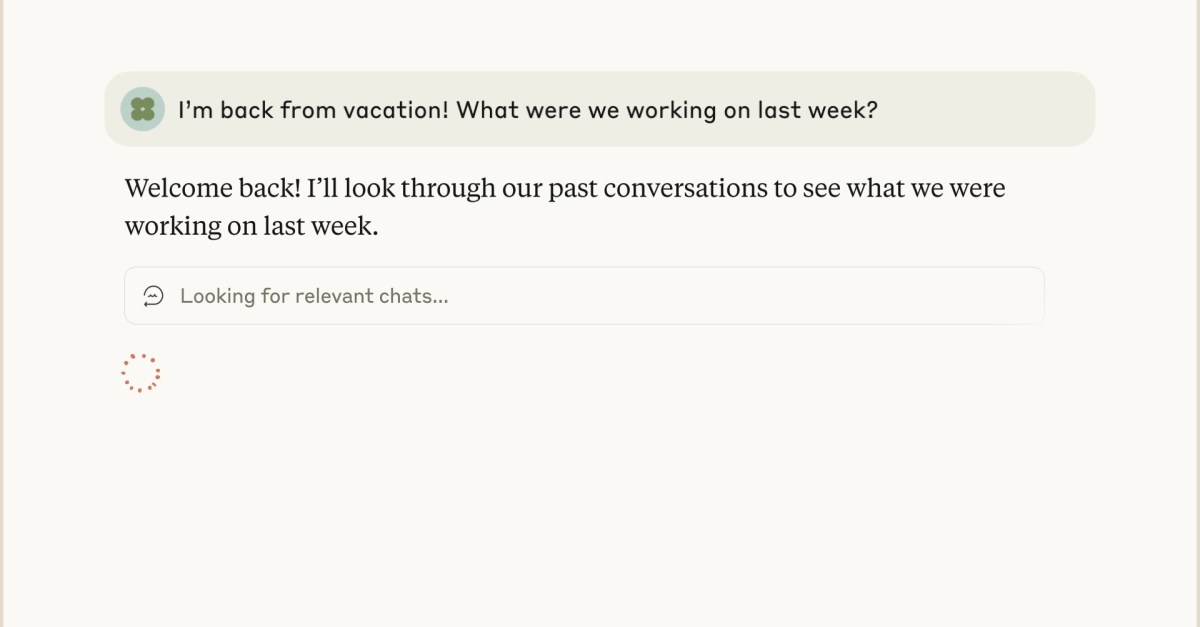
Anthropic rolled out a memory feature for Claude that lets the chatbot retrieve, read, and summarize past chats on demand, across web, desktop, and mobile — without building a persistent user profile.
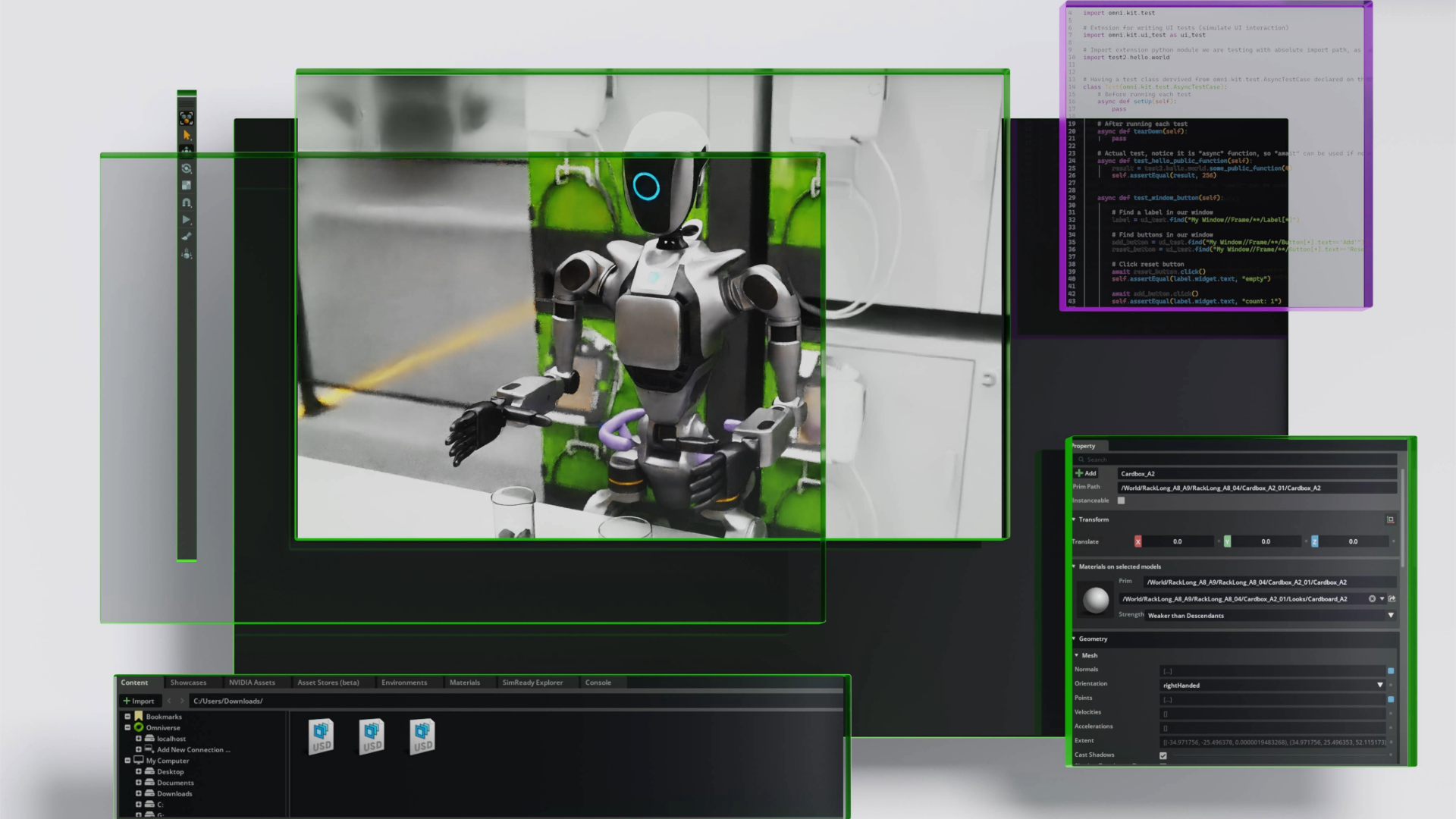
NVIDIA unveils updates to Omniverse libraries, Cosmos WFMs, and interoperability tools to enable physically accurate robot simulations, OpenUSD workflows, and accelerated AI-enabled robotics development.
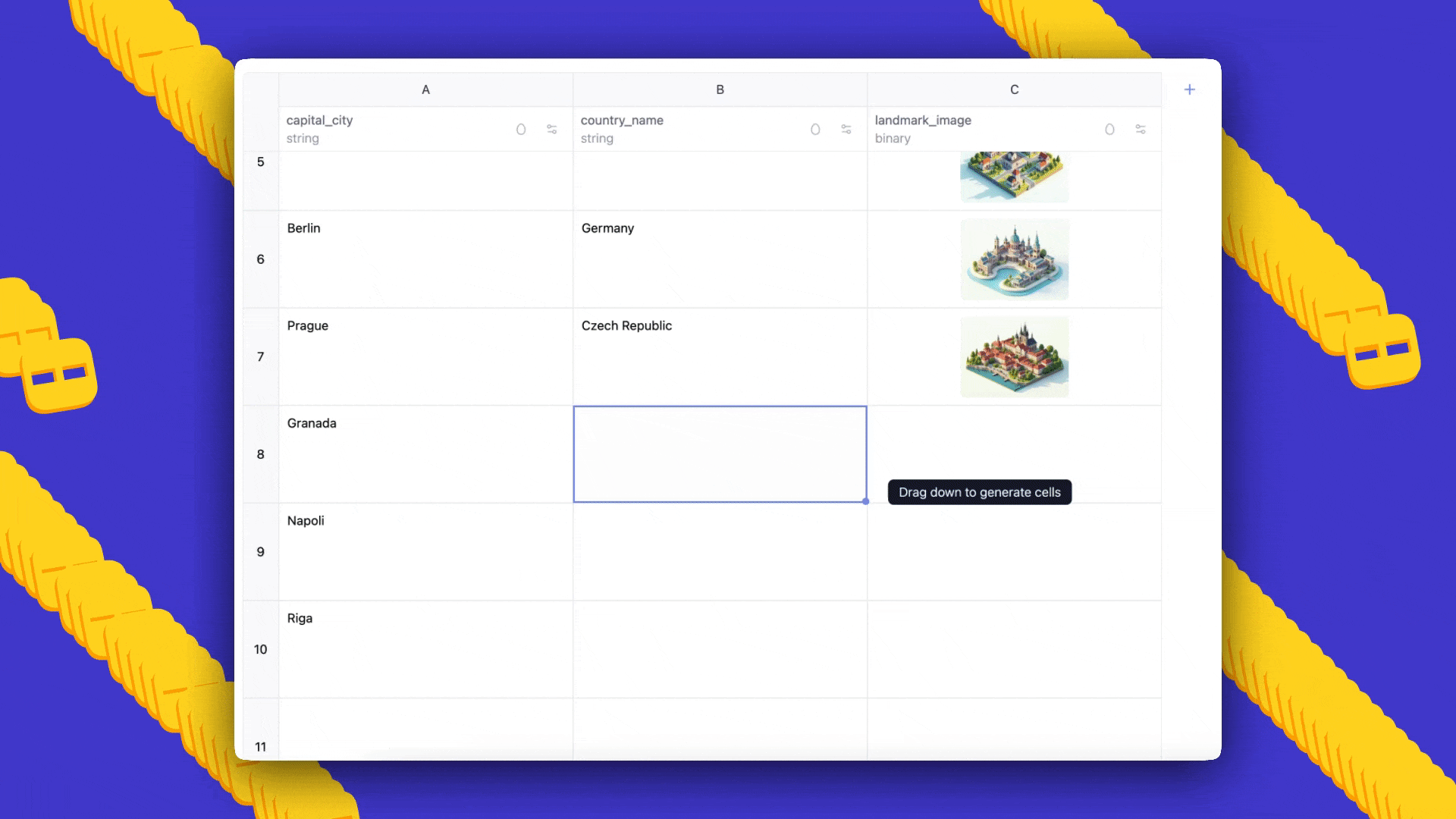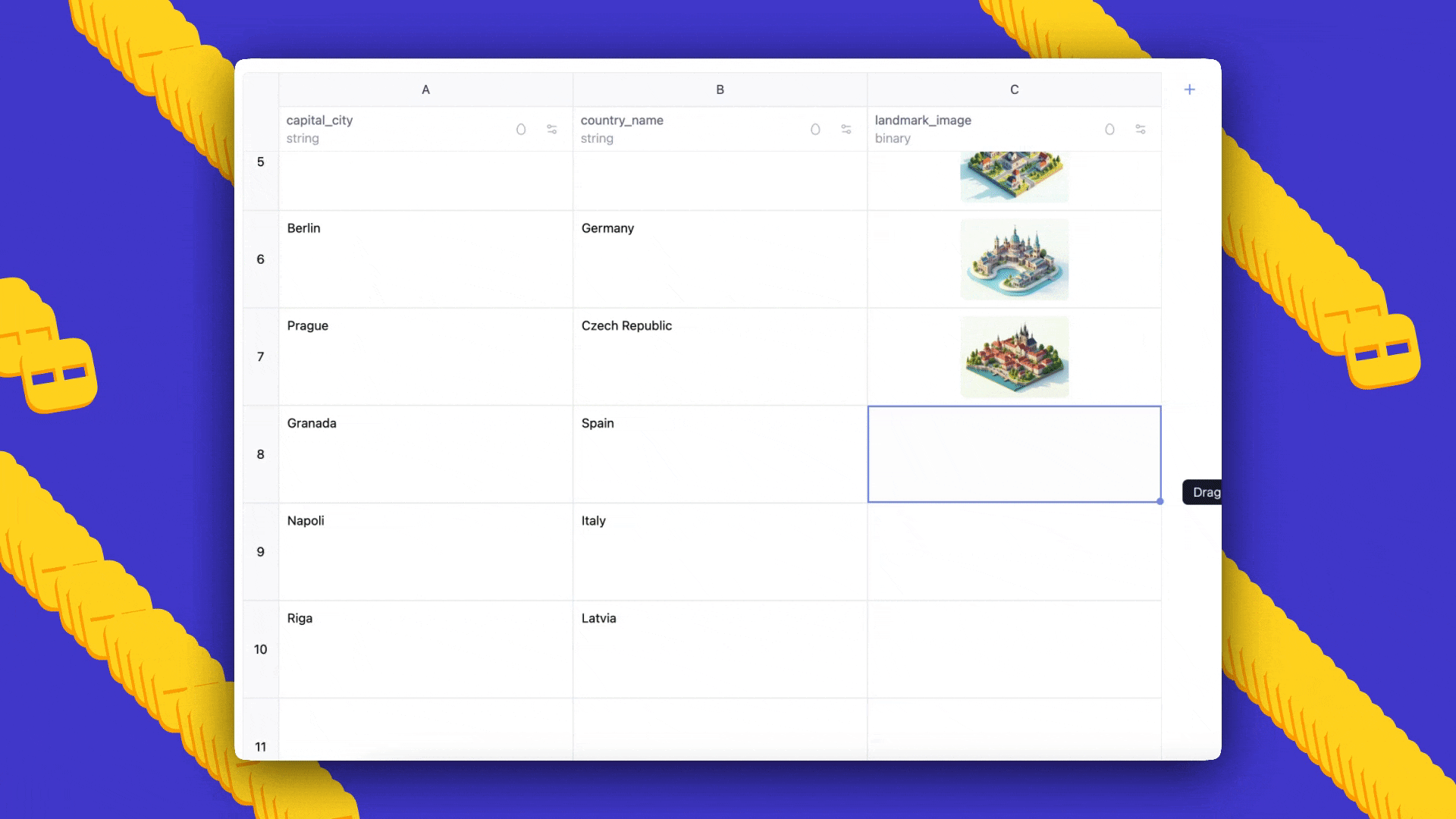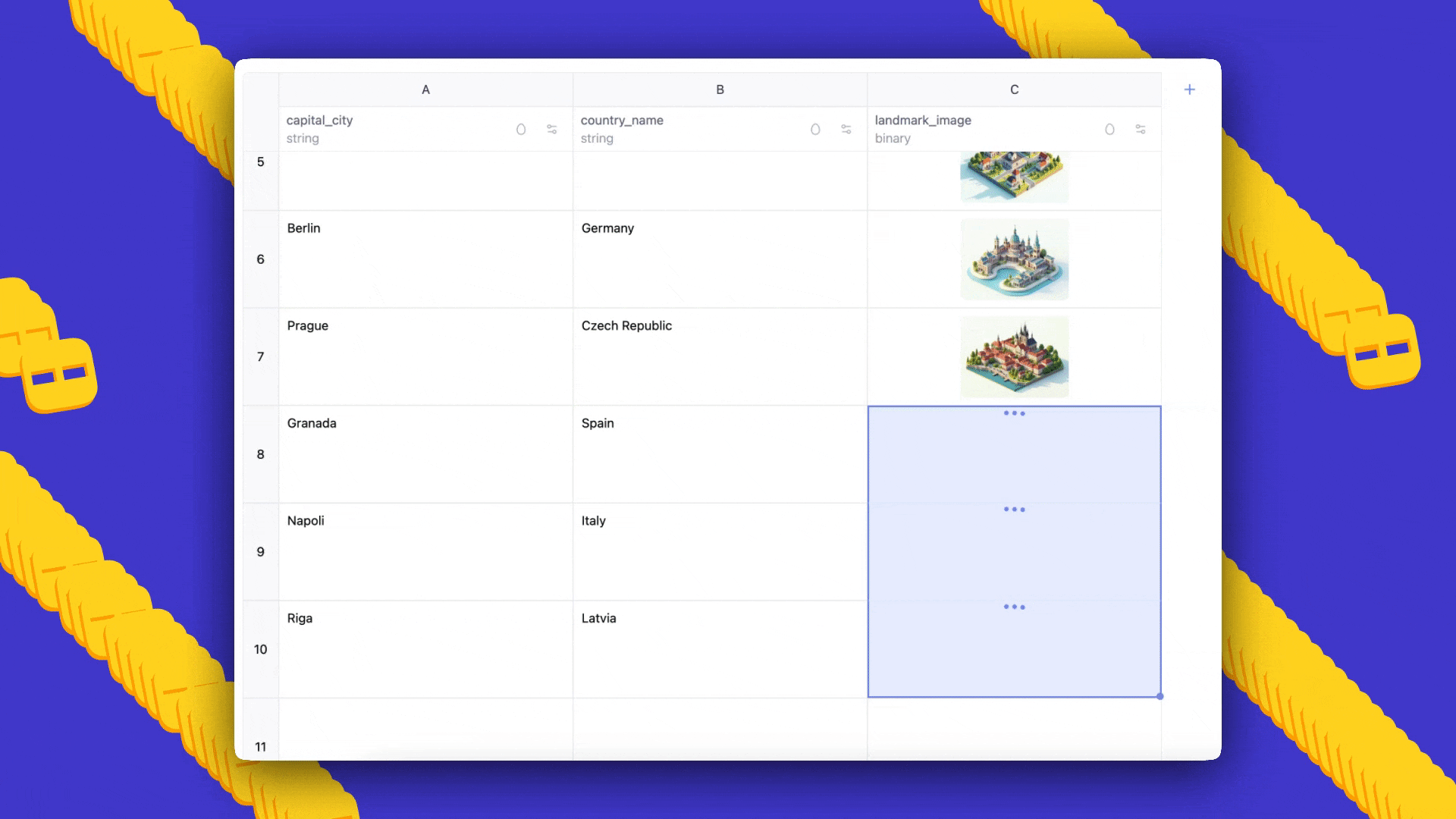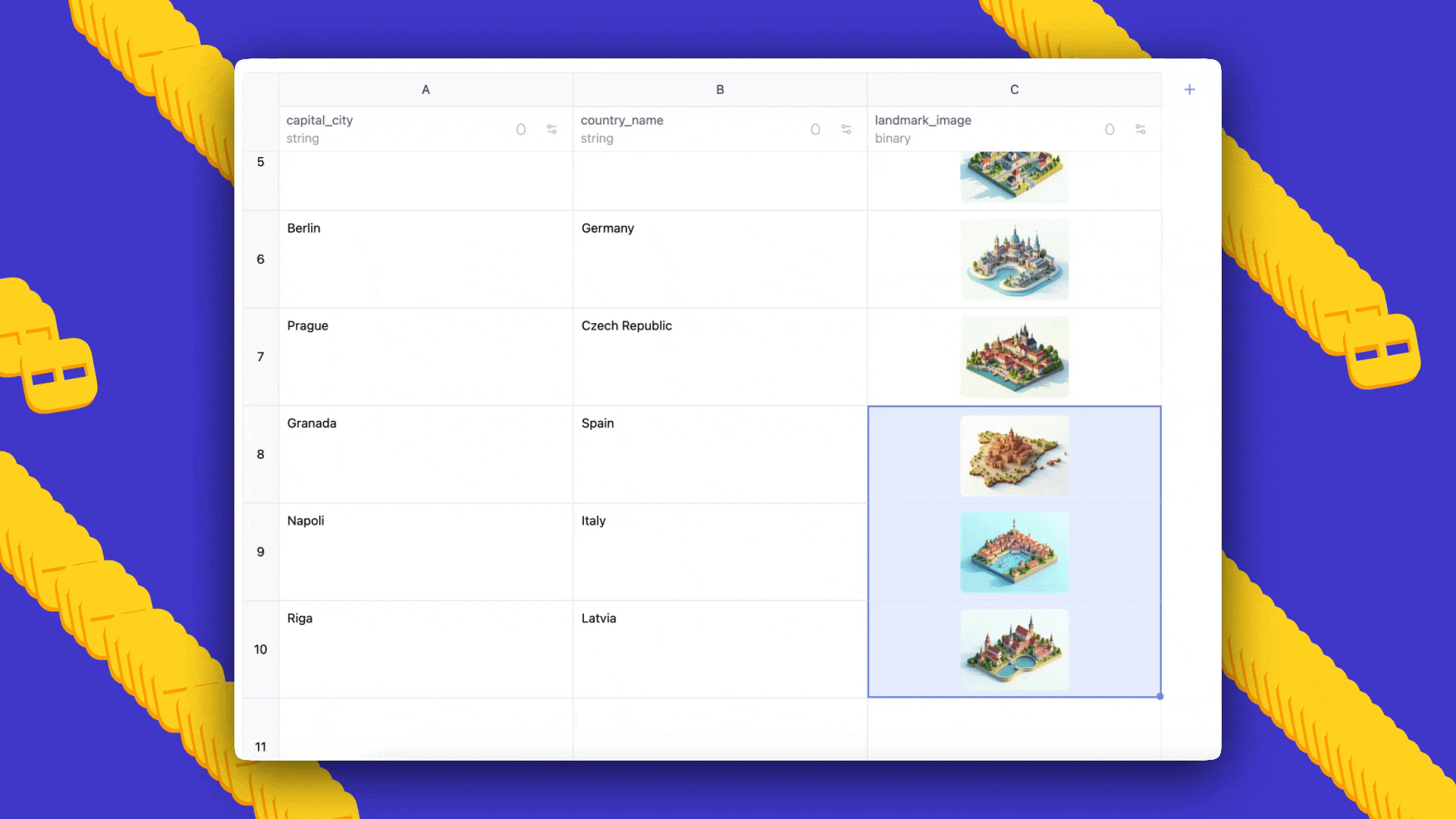
AI Sheets is an open-source, no-code tool from Hugging Face for building, transforming and enriching datasets using thousands of open models or local models. Try it in Spaces or deploy locally.

Overview of Accelerate's ND‑Parallel capabilities: combining data, tensor, sharded and context parallelism with Axolotl to scale large-model training across multi‑GPU and multi‑node environments.

This work introduces a vector-quantization based approximation to cross-attention for contextual biasing in ASR, enabling scalable, memory-efficient use of large bias catalogs with notable accuracy gains.
A concise resource on composing multiple parallelism strategies (DP, FSDP, TP, CP) with Accelerate and Axolotl to train large models across many GPUs, with guidance on configuration, use cases, and trade‑offs.
AI Sheets is an open-source, no-code tool for building, enriching, and transforming datasets with AI models. Deployable locally or on the Hub, it supports thousands of open models and lets you iterate with prompts, few-shot feedback, and model comparisons.

As multimodal AI models advance from perception to reasoning and autonomous action, new cognitive attack surfaces emerge. These threats target how AI systems solve problems across modalities, not just how they receive inputs.

OpenAI unveils GPT-5, its most capable AI system yet, featuring unified thinking, a real-time router, reduced hallucinations, and strong performance in coding, writing, health, and more.

OpenAI releases GPT-5 in the API with enhanced reasoning, new developer controls, and three serviceable sizes to optimize coding, agentic tasks, and tool use.

A Microsoft Research podcast features Dr. Umair Shah and Dr. Gianrico Farrugia discussing how AI reshapes public health, care delivery, the healthcare-research link, and the patient experience.

TRL expands multimodal alignment for Vision-Language Models with GRPO, GSPO, MPO, and native SFT support, plus ready-to-run scripts and notebooks to streamline post-training alignment.

Overview of TRL's multimodal alignment methods for vision-language models: GRPO, GSPO, MPO, plus native SFT support and DPO-based baselines.

Meta introduces Diff Risk Score (DRS), an AI-powered tool that predicts the risk of code changes causing production incidents, enabling safer and more productive software development.

CUDA Toolkit 13.0 introduces tile-based programming, unified Arm tooling across servers and embedded devices, and notable improvements in Nsight Compute, fatbin compression, and deployment workflows—positioning CUDA for future GPUs and Tensor Core architectures.

NVIDIA and OpenAI optimize gpt-oss-120b and gpt-oss-20b for accelerated inference on Blackwell, achieving up to 1.5M tokens per second on GB200 NVL72, with Day 0 support across cloud to edge.

A detailed analysis of the worst-case frontier risks when releasing open-weight LLMs, introducing Malicious Fine-Tuning (MFT) to probe biology and cybersecurity capabilities and comparing against open- and closed-weight baselines.

Open-weight reasoning models gpt-oss-120b and gpt-oss-20b, released under Apache 2.0 and the gpt-oss usage policy, are text-only and compatible with the Responses API, designed for agentic workflows with strong instruction following, tool use, and adjustable reasoning effort.

OpenAI unveils gpt-oss-120b and gpt-oss-20b—two open-weight LLMs designed for strong real-world performance at low cost. Licensed under Apache 2.0, they emphasize reasoning, tool use, and efficient on-device deployment across consumer hardware.

OpenAI releases two open-weight, mixture-of-experts models—GPT OSS 120B and GPT OSS 20B—utilizing MXFP4 4-bit quantization. They’re licensed Apache 2.0 with a minimal usage policy and are accessible via Hugging Face Inference Providers for on-device, on-prem, and cloud deployments.

OpenAI releases GPT OSS, a pair of 120B and 20B mixture-of-experts models with MXFP4 4-bit quantization, licensed Apache 2.0, and delivered via Hugging Face Inference Providers for on-device and server deployments.

Two open-weight OpenAI models (gpt-oss-120b and gpt-oss-20b) using mixture-of-experts and MXFP4 quantization for fast, memory-efficient reasoning. Licensed Apache 2.0; designed for private/local deployments and on-device use, with Hugging Face Inference Providers integration.

Meta’s Reality Labs is pursuing wrist-worn devices using surface electromyography (sEMG) to enable intuitive control across users. This piece covers the podcast discussion on generalization challenges and the quest for a generic neuromotor interface.

Cloudflare says Perplexity ignored robots blocks, masked its crawler identity, and scraped content from sites that asked AI scrapers not to access them. Perplexity disputes the claim.
Figma’s AI-driven roadmap embeds capabilities from code generation to collaborative agents, reshaping how teams prototype, design, and build digital products.

Intercom shares three practical lessons from building a scalable AI platform that powers Fin, their AI Agent, highlighting early experimentation, rigorous evaluation, and a modular architecture that evolves with AI advances.

ExecuTorch is Meta’s open-source PyTorch inference framework for on-device ML across its family of apps, delivering lower latency, better privacy, and improved performance on Android and iOS.

Hugging Face expands data efficiency with Parquet CDC, enabling content-defined chunking in PyArrow and Pandas and leveraging the Xet storage layer to dramatically reduce data transfer and storage costs.
Parquet Content-Defined Chunking (CDC) extends PyArrow and Pandas, enabling efficient, cross-repository deduplication on Hugging Face’s Xet storage layer to cut Parquet transfer and storage costs.
Enable Parquet CDC with Hugging Face's Xet storage to deduplicate data chunks across files and repositories, reducing upload/download size and storage costs.

TimeScope introduces a new open-source benchmark to measure how vision-language models process long videos by inserting short needles and evaluating retrieval, synthesis, localization, and motion analysis.

Meta details its approach to maintaining reliability in its AI hardware at scale, covering fault categories, detection of silent data corruptions, and strategies that keep large training clusters like Llama 3 operational.

Ettin introduces the first state-of-the-art paired encoder-only and decoder-only models trained with identical data and recipes, measuring apples-to-apples performance across tasks and scales.

Meta joins the Kotlin Foundation as a gold member to accelerate Kotlin adoption across Android. The move supports Meta’s Java-to-Kotlin migration, open source tooling, and grants to foster a robust Kotlin ecosystem.

A concise resource outlining why multimodal, scale-driven approaches are unlikely to yield human-level AGI and why embodied world models are essential.

Northwind Climate maps climate-conscious behavior beyond demographics, identifying 'climate doers' and other groups via surveys. The platform offers a subscription-based data and analytics service, plus AI tools for marketing insights.

As data centers expand to meet AI-driven demand, solar PPAs over 100 MW have surged globally in 2025. Major deals across Meta, Microsoft, Cisco, Amazon, and others illustrate solar’s near-term advantage in cost, deployment speed, and scalability.

Nvidia teams with EPRI to form the Open Power AI Consortium, building open-source, domain-specific AI models to tackle grid challenges driven by AI workloads and rising data-center demand.

Step-by-step guide to disable Apple Intelligence on iPhone, iPad, and Mac. Includes how to turn off Siri for privacy and an overview of Apple’s Private Cloud Compute approach.

As AI drives soaring data-center power demand, 2025 hinges on nuclear and fusion potential, hydrogen subsidy risks, and shifting investment as grids, regulators, and big tech race to secure electricity.

TechCrunch catalogs 49 U.S.-based AI startups that raised at least $100M in 2024, framing the year with major megafunds from OpenAI and xAI and a funding backdrop dominated by AI rounds.
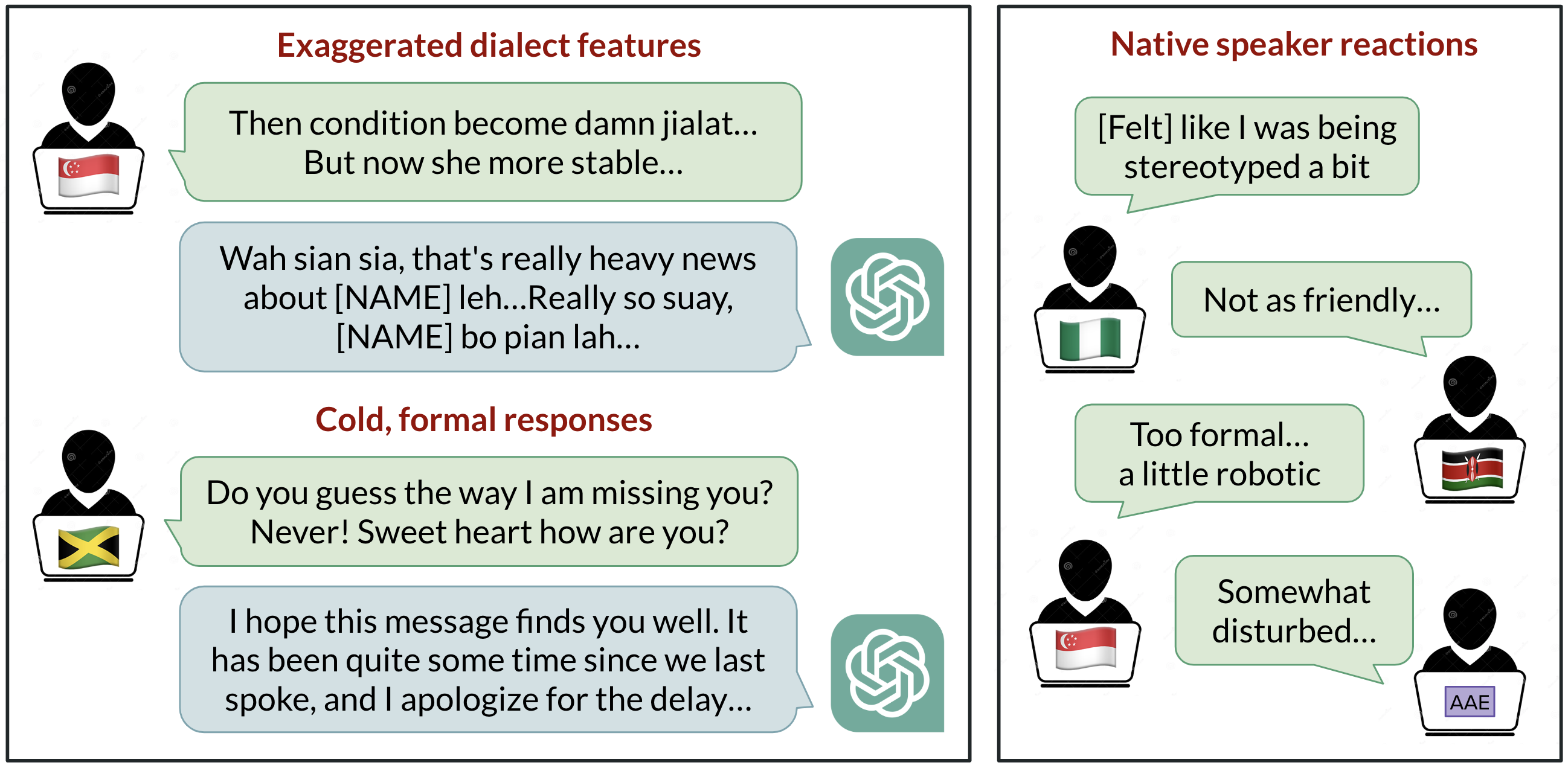
Analysis of how ChatGPT responds to different English dialects, highlighting biases against non-standard varieties and implications for global users.

Explores purposeful dialogue in LLM chatbots, arguing multi-turn interactions better align AI with user goals and enable collaboration, especially in coding and personal assistant use cases.
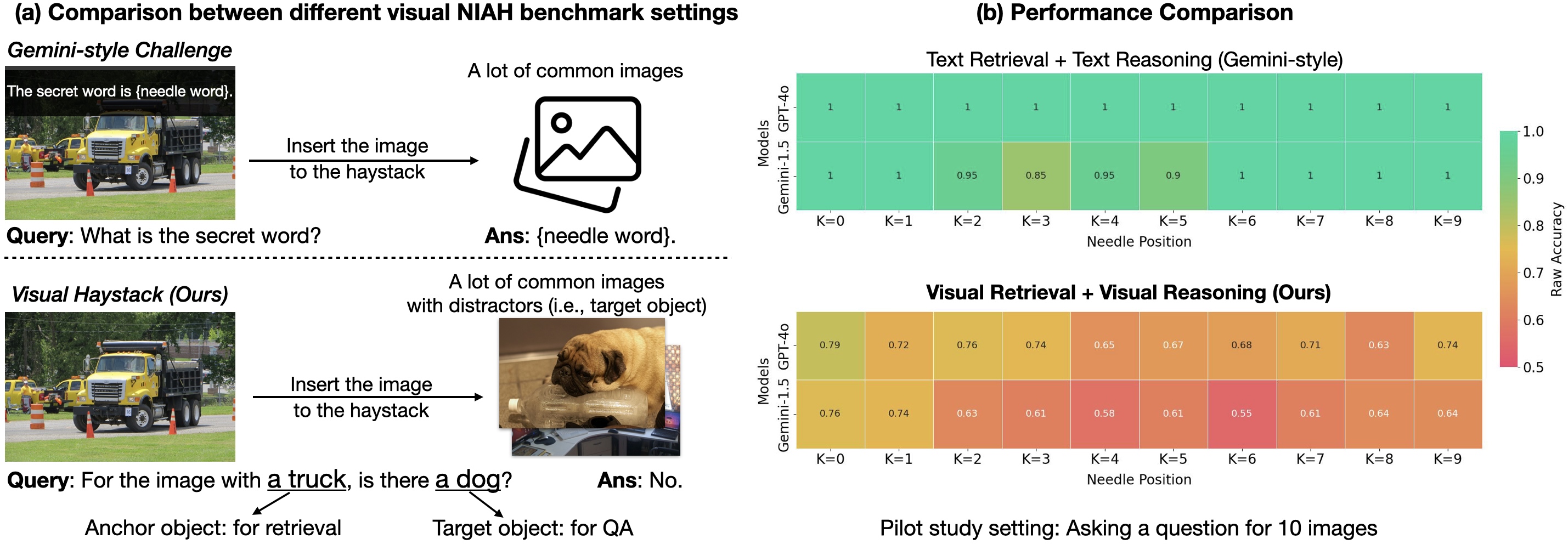
A new MIQA benchmark tests Large Multimodal Models on visual retrieval and reasoning across 1–10K images, revealing key limitations and introducing MIRAGE, a single-stage approach to scale LMMs.

Benchmark for long-context visual reasoning across large, uncorrelated image sets; introduces MIRAGE to extend LMMs beyond single-image VQA.
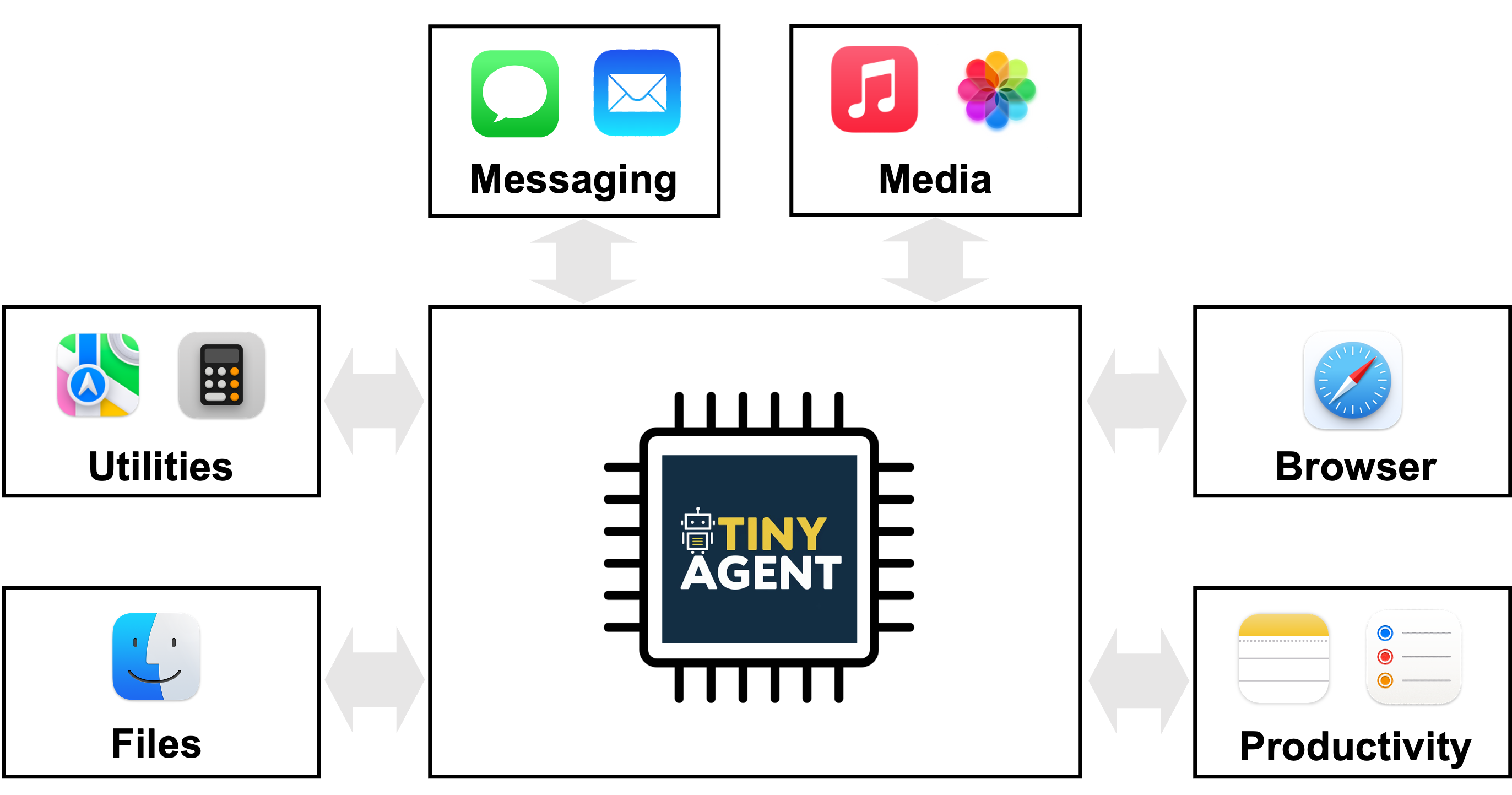
TinyAgent shows small language models can be fine-tuned for reliable function calling and edge deployment, using curated synthetic data, an LLMCompiler planner, and a Tool RAG approach to power private, low-latency agentic workflows.

An in-depth look at how large language models (LLMs) relate to financial markets: token counts, predictability limits, multimodal approaches, synthetic data, residualization, and practical implications for quant and fundamental work.

Overview of how LLMs can be applied to financial markets, including autoregressive modeling of price data, multi-modal inputs, residualization, synthetic data, and multi-horizon predictions, with caveats about market efficiency.

Curated overview of key studies showing how AI systems reproduce and amplify gender bias, with concrete measures, benchmarks, and mitigations across embeddings, vision, NLP, and generative models.

Survey of key work measuring gender bias in AI, across word embeddings, coreference, facial recognition, QA benchmarks, and image generation; discusses mitigation, gaps, and the need for robust auditing.

A deep dive into Mamba, a State Space Model (SSM) based backbone designed for long-context sequences, offering Transformer-like performance with improved efficiency.
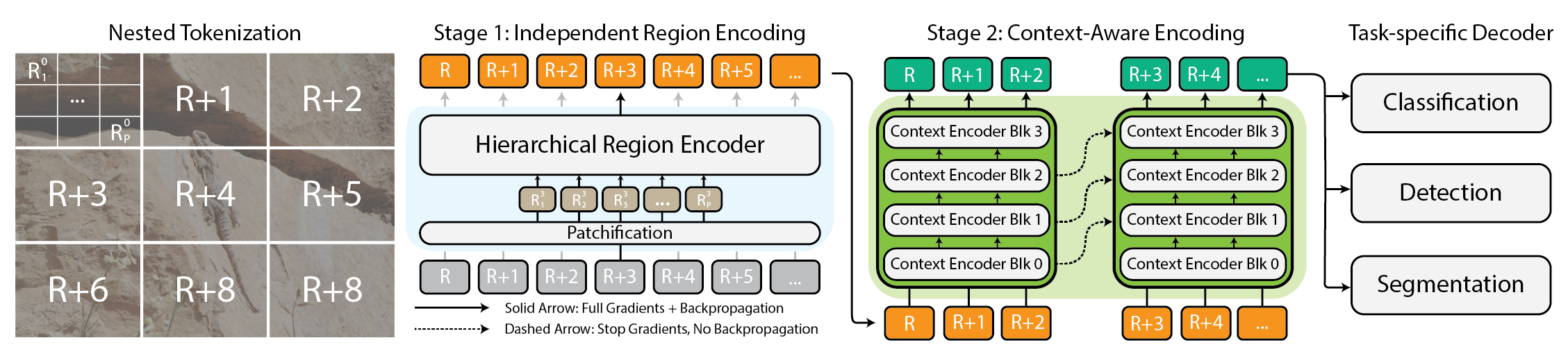
xT enables end-to-end modeling of gigapixel-scale images on modern GPUs using nested tokenization, region encoders, and long-context vision, delivering high fidelity and context on images up to 29,000×25,000 pixels.

Directory of BAIR Lab PhD graduates featuring research interests, advisor(s), and contact details to facilitate collaboration and recruitment.

Explores how LLMs can augment perception, planning, and scenario generation for autonomous vehicles, highlighting approaches like Talk2BEV and GAIA‑1, while discussing trust, reliability, and deployment considerations.

Survey of how large language models (LLMs) could augment autonomous driving across perception, planning, and generation, with examples, challenges, and early results.

Foundational concepts on AI consciousness, including Block's classifications, Chalmers' easy vs hard problems, and the AI Moral Status Problem, explained for practitioners.

Overview of AI consciousness debates, definitions, and moral status implications. Highlights Block's distinctions (self-, monitoring-, access-, p-consciousness) and Chalmers' easy vs hard problems; discusses need for cross-disciplinary work.