xT: End-to-end Modeling of Extremely Large Images on GPUs
Sources: http://bair.berkeley.edu/blog/2024/03/21/xt, http://bair.berkeley.edu/blog/2024/03/21/xt/, BAIR Blog
Overview
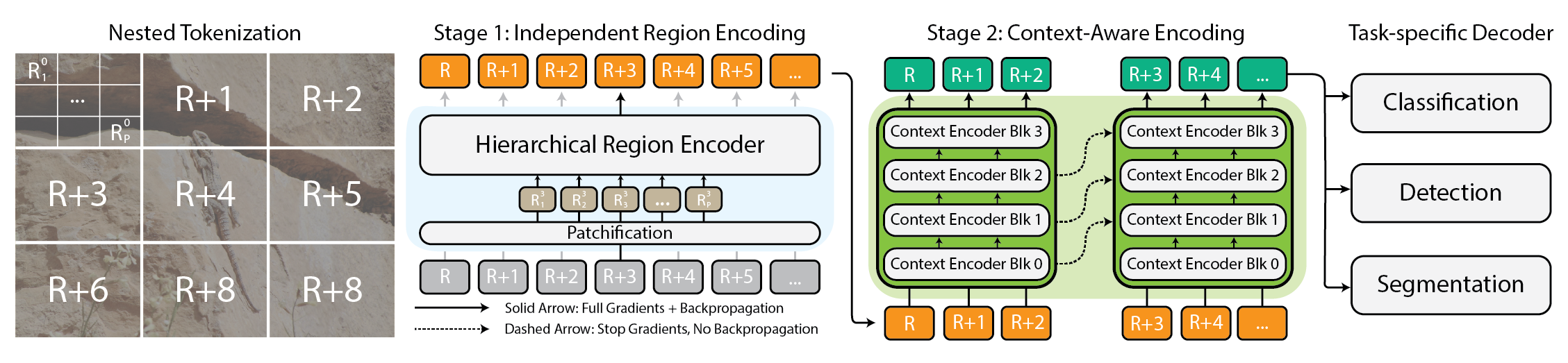
Modeling extremely large images has become a practical necessity as cameras and sensors generate gigapixel-scale data. Traditional approaches struggle because memory usage grows quadratically with image size, forcing down-sampling or cropping that loses important information and context. xT offers a new framework to model large images end-to-end on contemporary GPUs while effectively aggregating global context with local details. At its core, xT introduces nested tokenization, a hierarchical breakdown of an image into regions and sub-regions that are processed by specialized components before being stitched together to form a global representation. In xT, the image is divided into regions through nested tokenization. Each region is handled by a region encoder, which can be a state-of-the-art vision backbone such as hierarchical vision transformers like Swin or HierA, or CNNs like ConvNeXt. The region encoder acts as a local expert that converts regions into detailed representations in isolation. To assemble a global picture, the context encoder takes these region-level representations and models long-range dependencies across the entire image. The context encoder is typically a long-sequence model; the authors experiment with Transformer-XL and a variant named Hyper, as well as Mamba, though Longformer and other long-sequence models are also viable options. The magic of xT lies in its combination of nested tokenization, region encoders, and context encoders. By first dissecting the image into manageable pieces and then integrating them, xT preserves image fidelity while incorporating distant information. This end-to-end operation enables processing of massive images on modern GPUs, avoiding the memory bottlenecks that hamper traditional methods. xT is evaluated on diverse and challenging benchmarks, spanning standard baselines and large-image tasks. It achieves higher accuracy on downstream tasks with fewer parameters and substantially lower memory per region compared to state-of-the-art baselines. The authors demonstrate the ability to model images as large as 29,000 × 25,000 pixels on 40 GB A100 GPUs, whereas comparable baselines run out of memory at about 2,800 × 2,800 pixels. The approach is tested on tasks such as fine-grained species classification (iNaturalist 2018), context-dependent segmentation (xView3-SAR), and object detection (MS-COCO). Beyond the technical details, xT enables scientists and clinicians to see both the forest and the trees: in environmental monitoring, it supports understanding broad landscape changes alongside local details; in healthcare, it can help detect diseases by considering wide context and fine-grained patches. While the authors do not claim to solve every problem, they position xT as a meaningful step toward models that can juggle large-scale context and intricate details end-to-end on contemporary GPUs. A complete treatment is available as an arXiv preprint, and the project page provides links to released code and weights.
Key features
- Nested tokenization: hierarchical breakdown of images into regions and sub-regions for scalable processing
- Region encoders: local expert backbones (Swin, HierA, ConvNeXt, etc.) that transform regions into detailed representations
- Context encoders: long-sequence models (Transformer-XL, Hyper, Mamba; Longformer and others possible) that stitch regional representations across the image
- End-to-end on GPUs: large images modeled end-to-end with manageable memory footprints
- Global context with local detail: preserves fine-grained information while integrating distant context
- Competitive benchmarks: higher accuracy with fewer parameters and lower memory per region on tasks like iNaturalist 2018, xView3-SAR, and MS-COCO
- Large-image capability: demonstrated support for images up to 29,000 × 25,000 on 40 GB A100 GPUs while baselines fail earlier
- Open science angle: released code and weights on the project page; arXiv paper available
Common use cases
- Fine-grained species classification on very large imagery (iNaturalist 2018)
- Context-dependent segmentation for large scenes (xView3-SAR)
- Detection in large-scale datasets (MS-COCO)
- Environmental monitoring: enables viewing broad landscape changes alongside local details
- Healthcare imaging: supports diagnosing through both overview and patch-level information
Setup & installation
Note: The source does not provide exact setup or installation commands. Please refer to the project page for code and weights.
# Setup & installation
# Exact commands are not provided in the source.
# Please refer to the project page for code and weights.Quick start
This quick start is a conceptual outline illustrating the intended workflow; it is not a runnable recipe provided by the source.
# Quick start (conceptual)
# Load a large image (gigapixel scale)
image = load_large_image('path/to/giant_image.png')
# Nested tokenization into regions and sub-regions
regions = nested_tokenize(image)
# Local processing for each region
local_features = [region_encoder(r) for r in regions]
# Fuse regional features with global context
global_context = context_encoder(local_features)
# Make task-specific predictions
preds = head_classifier(global_context)
print(preds)Pros and cons
- Pros
- End-to-end handling of massive images on contemporary GPUs
- Maintains local detail while integrating global context
- Lower memory per region with potentially fewer parameters than baselines
- Demonstrated capability to handle very large images (29k × 25k) where traditional baselines fail
- Flexible backbone choices for region encoders and context models
- Applicable across diverse domains including ecology and healthcare
- Cons
- Requires a coordinated setup of region and context encoders and potentially long-sequence models
- The exact installation and training steps are not specified in the source
- Still a research framework; practical deployment may require careful engineering and hardware considerations
Alternatives (brief comparisons)
- Down-sampling: reduces image size before processing but loses information and context
- Cropping: processes smaller patches but can miss long-range dependencies and global context
- Long-range transformers (e.g., Longformer, Transformer-XL variants): used as context encoders in xT; other long-sequence models may be viable alternatives
- Single-backbone processing at full resolution with memory optimizations: not applicable to truly gigapixel images without specialized architectures | Approach | Strengths | Limitations |---|---|---| | Down-sampling | Simple, low memory | Loses detail and context across the whole image |Cropping | Local focus; modular | Breaks global coherence; context gaps |xT (nested tokenization) | End-to-end, global context with local detail | More complex to implement; relies on multiple components |Other long-sequence backbones | Handles long-range dependencies | Potentially high memory/time costs; integration complexity |
Pricing or License
Licensing information is not provided in the source. The project page mentions released code and weights, but no explicit license is stated here.
References
More resources

CUDA Toolkit 13.0 for Jetson Thor: Unified Arm Ecosystem and More
Unified CUDA toolkit for Arm on Jetson Thor with full memory coherence, multi-process GPU sharing, OpenRM/dmabuf interoperability, NUMA support, and better tooling across embedded and server-class targets.

Cut Model Deployment Costs While Keeping Performance With GPU Memory Swap
Leverage GPU memory swap (model hot-swapping) to share GPUs across multiple LLMs, reduce idle GPU costs, and improve autoscaling while meeting SLAs.

Improving GEMM Kernel Auto-Tuning Efficiency with nvMatmulHeuristics in CUTLASS 4.2
Introduces nvMatmulHeuristics to quickly select a small set of high-potential GEMM kernel configurations for CUTLASS 4.2, drastically reducing auto-tuning time while approaching exhaustive-search performance.

Make ZeroGPU Spaces faster with PyTorch ahead-of-time (AoT) compilation
Learn how PyTorch AoT compilation speeds up ZeroGPU Spaces by exporting a compiled model once and reloading instantly, with FP8 quantization, dynamic shapes, and careful integration with the Spaces GPU workflow.

How to spot and fix 5 pandas bottlenecks with cudf.pandas (GPU acceleration)
A developer-focused resource outlining five common pandas bottlenecks, practical CPU and GPU fixes, and drop-in GPU acceleration with cudf.pandas for scalable data workflows.

Inside NVIDIA Blackwell Ultra: The Chip Powering the AI Factory Era
An in‑depth profile of NVIDIA Blackwell Ultra, its dual‑die NV‑HBI design, NVFP4 precision, 288 GB HBM3e per GPU, and system‑level interconnects powering AI factories and large‑scale inference.